
Minimal Is No Longer Enough
Why AI-Scale Vulnerability Discovery Changes Container Security
On April 7, Anthropic reported CVE-2026-5747 through AWS's Vulnerability Disclosure Program. It was an out-of-bounds write in Firecracker's virtio PCI transport layer. A guest with root privileges, meaning any compromised workload, could crash the Firecracker VMM process or potentially execute arbitrary code on the host. AWS quickly patched it, and no AWS services were affected.
The timing here is not coincidental. AI-assisted vulnerability discovery has crossed a threshold where even the most minimal, best-engineered VMM code will be fully explored faster than it can be audited and patched. That changes which container isolation architectures are structurally sound — and which are simply on a patching treadmill they cannot exit.
The Isolation Spectrum of Container Isolation Models: From Shared Kernel to Hardware Boundary
Container isolation exists on a spectrum. At one end, you share the host kernel with every container on the node. At the other, you isolate workloads behind hardware boundaries with no shared software. Every solution on the market sits somewhere on this spectrum, and its position affects what happens when a workload is compromised.
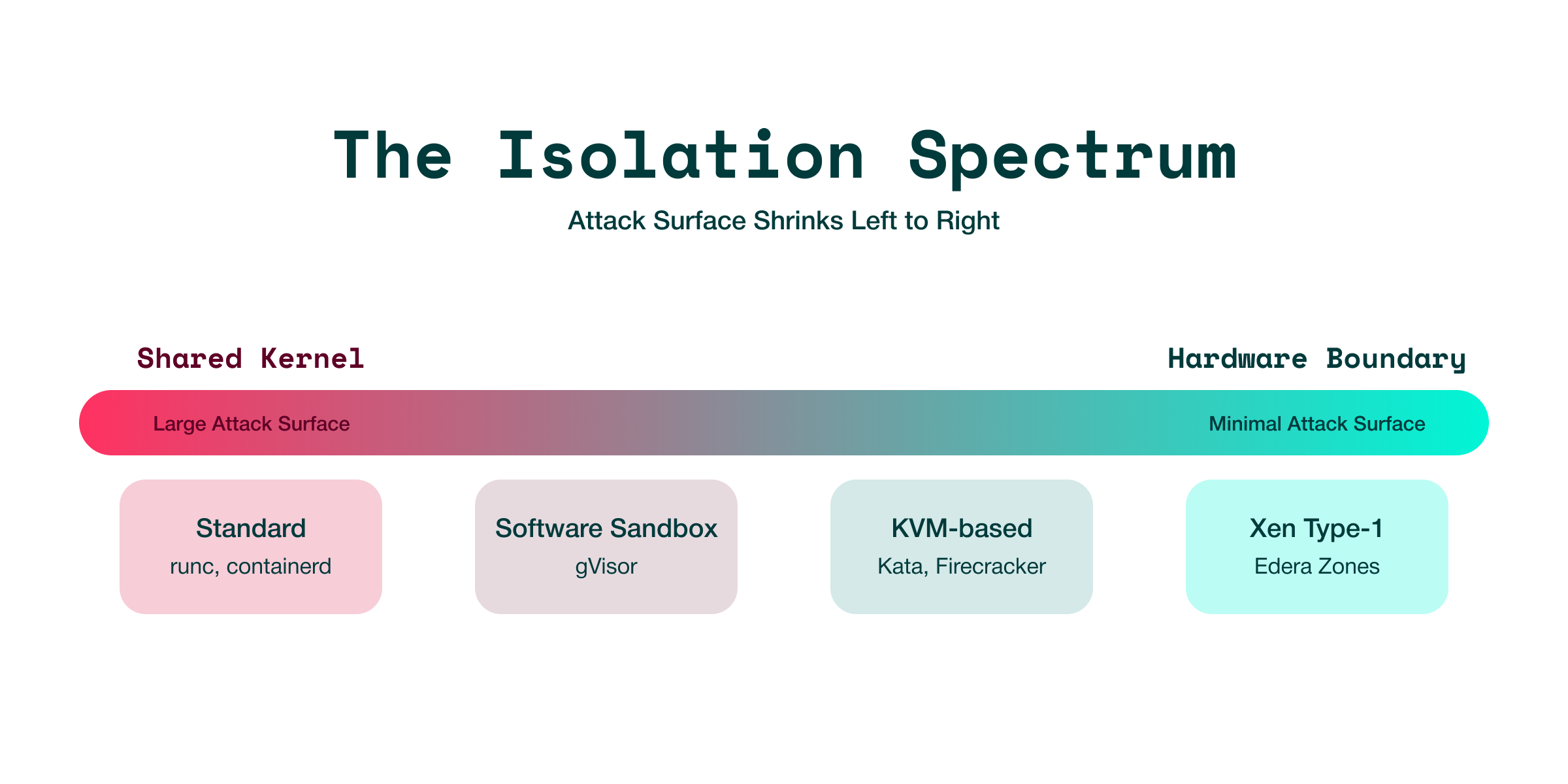
Standard Containers: Shared-Kernel Isolation and Its Limits
Standard containers (runc, containerd, CRI-O) isolate workloads using Linux namespaces, cgroups, seccomp filters, and LSM profiles. These are process-level boundaries enforced by a single shared kernel.
The shared kernel is the problem. Every container on a node goes through the same kernel via the same syscall interface. Seccomp filters reduce the surface, but the remaining attack surface is still the Linux kernel, which contains millions of lines of C with a constant stream of privilege escalation vulnerabilities. CVE-2022-0185, CVE-2024-1086, and the recent Opus 4.6 kernel findings show different symptoms of the same structural issue: the syscall boundary is too broad, and the kernel is too complex for namespace isolation to be a secure boundary.
Container escapes from this model happen regularly. When one succeeds, the attacker gains access to the host and every other container on the node.
gVisor: Software Boundary, Still Shared Kernel
Google's gVisor replaces the shared kernel with a user-space kernel called Sentry. Instead of making syscalls directly to the host kernel, guest syscalls are intercepted and reimplemented in Go by the Sentry process. The host kernel only sees Sentry's syscalls, creating a much narrower interface.
This is a significant improvement over shared-kernel containers. The attack surface shrinks from the full Linux syscall interface to about 200 syscalls that Sentry reimplements. A Sentry escape results in an unprivileged process on the host rather than kernel-level access, as Sentry itself is sandboxed with seccomp.
The limitation is structural: the host kernel is still shared. Sentry's syscalls can still reach it. A kernel vulnerability accessible from Sentry's syscall profile can still escalate. The boundary here is software, not hardware, and software boundaries are inherently weaker than hardware ones.
How AI-Scale Vulnerability Discovery Changes the Security Calculus
We mentioned that Anthropic reported CVE-2026-5747.
Anthropic disclosed that Claude had systematically discovered over 500 validated high-severity vulnerabilities, including remotely exploitable bugs in the Linux kernel that had gone undetected for over two decades. Researcher Nicholas Carlini showed near 100% success rates for vulnerability identification when guiding AI through source repositories. The UK AI Security Institute's SandboxEscapeBench study found that Claude Opus 4.5 and GPT-5 each escaped standard containers about half the time and achieved 100% escape rates on common misconfigurations.
CVE-2026-5747 fits this pattern. A frontier AI model found an out-of-bounds write in a Rust codebase created by one of the best security engineering teams in the industry, in a project that has been audited, fuzzed, and battle-tested through billions of Lambda invocations. The bug was in virtio PCI queue configuration, exactly the kind of intricate, stateful, unsafe-heavy code that AI models excel at analyzing because they can hold the entire interaction state machine in context while systematically probing edge cases.
This alters the reasoning behind "minimal attack surface" arguments.
The traditional security belief was that a small codebase with a strong team and good tools would have few undiscovered vulnerabilities. Reducing the surface area was enough because human auditors and fuzzers have limited capacity – if the surface is small enough, it would eventually be fully explored. But AI-assisted vulnerability discovery does not have limited capacity. It scales with computing power. A 50,000-line Rust codebase that might take a human security team months to thoroughly audit can be fully explored in hours. Every device register, every queue operation, every edge case in any state transition.
What was a 50,000-line attack surface yesterday is now 50,000 lines that an AI can fully explore by next quarter. The vulnerability pipeline does not close when the codebase is small; it simply gets explored more quickly. If the architecture requires a VMM, that VMM will likely contain bugs, and those bugs will be found faster than they can be fixed.
The winning move isn't zero attack surface, it's the smallest exploitable surface and, more importantly, the shape of that surface. When an architecture includes a VMM, that changes the shape of what’s exploitable. Not a small VMM. No VMM. Not a small device emulation surface. No device emulation surface. Not a narrow syscall interface. No shared kernel at all.
This is why the difference between Edera's architecture and every KVM-based solution is not just a minor detail. It's a fundamental change. Firecracker can patch CVE-2026-5747. They cannot patch the fact that virtio device emulation exists and will keep being explored by increasingly capable models. Edera doesn't have virtio device emulation to patch.
KVM-Based Solutions: Hardware Isolation with a VMM Attack Surface
Kata Containers, Firecracker, and Cloud Hypervisor use KVM, a Linux kernel module that turns the host kernel into a hypervisor. Each workload runs in its own virtual machine with its own kernel, isolated by hardware-enforced memory partitioning (EPT/NPT, VT-x/SVM).
This creates a hardware boundary that is tough to breach. A guest kernel exploit affects only that VM's kernel, not the host's. Memory isolation is enforced by the CPU, rather than software checks. This is a clear improvement over namespace isolation.
However, KVM-based solutions share a structural trait: every VM has a user-space VMM process. This component – QEMU, Cloud Hypervisor, or Firecracker – emulates devices, manages memory mappings, and handles I/O for the guest. The VMM runs on the host, and the guest interacts with it through virtio queues, MMIO registers, and PCI configuration space. And the VMM becomes the attack surface.
The VMM Problem: Untrusted Guest Input, Host-Side Privileges
CVE-2026-5747 highlights this issue. The vulnerability lies in Firecracker's handling of virtio queue configuration registers after device activation. The guest modifies PCI registers, and Firecracker's virtio transport code processes those modifications, leading to an out-of-bounds write.
This is the same type of bug that has plagued QEMU for over a decade. VENOM (CVE-2015-3456) was a floppy disk controller bug. CVE-2020-14364 involved USB EHCI. CVE-2021-20255 was about e1000 network emulation. The specific device may change, but the pattern is consistent. The VMM processes untrusted input from the guest and acts upon it with host-side privileges. Every emulated device presents a potential escape route.
Firecracker reduces this threat by emulating only five devices, using Rust's memory safety features, and sandboxing the VMM process with seccomp and a jailer. These choices lower the chances of bugs and limit their potential damage. However, CVE-2026-5747 shows that this does not eliminate the risk. Rust protects against use-after-free and buffer overflows in safe code, but virtio device emulation involves unsafe pointer arithmetic, DMA mapping, and shared memory. These are the areas where Rust's safety guarantees are weakest.
The attack surface is ingrained in the architecture. As long as there is a user-space VMM process interpreting guest-controlled data, that process is a valid escape target.
How Your Kata VMM Choice Changes Your Blast Radius
Kata Containers requires specific discussion because its security depends heavily on the chosen VMM – often a choice operators make without realizing it.
.png)
QEMU is often the default VMM. It emulates USB controllers, display adapters, audio devices, legacy BIOS hardware, and many storage and network backends. Much of this code is in C and has a long history of CVEs.
"Disaggregation" refers to how well the VMM is separated from the host. In a well-disaggregated setup, the VMM runs unprivileged and with limited access to the host. This means a VMM escape does not immediately give you root access. In a poorly disaggregated setup – common with Kata + QEMU – the VMM might run as root with extensive access to files and networks. A QEMU escape in that configuration effectively is game over.
The security difference between Kata + QEMU and Kata + Firecracker is significant enough to put them in different categories of isolation. However, operators who deploy Kata "out of the box" may not be aware of the configuration they are using.
Edera on Xen: Type-1 Hypervisor with No VMM and No Device Emulation
Edera uses Xen, a Type-1 hypervisor that operates directly on hardware, bypassing the host kernel. Each workload runs in a zone—a Xen DomU with its own kernel, isolated at the hardware level by the hypervisor.
The architectural difference from KVM-based solutions is clear: there is no user-space VMM. No QEMU, no Firecracker, no Cloud Hypervisor. The zone communicates with the host through only one channel: Inter-Domain Messaging (IDM), a structured protocol over Xen shared memory. The host-side IDM handler is a Rust daemon that verifies zone identity through its own lookup table, not any claims made by the zone.
Edera’s attack surface is Xen hypercalls, IDM, event channels and grant tables, not device emulation and VMMs.
This deserves explanation, because it's natural to ask: if there's no VMM, how does the zone do I/O?
IDM over Shared Memory: Why Xen Replaces Device Emulation Entirely
In KVM-based solutions, the guest handles I/O by interacting with emulated hardware devices. It writes to MMIO registers, fills virtio descriptor chains, and manipulates PCI configuration space. Each register write triggers a VMEXIT. A user-space VMM process, such as QEMU, Firecracker, or Cloud Hypervisor, wakes up to emulate the device's behavior. It decodes the register, updates internal state, processes the command, and then resumes the guest. The VMM is pretending to be hardware, managing register files, state machines, and DMA descriptors for each emulated device.
The VMM is the target for attacks because it must accurately read the guest's register writes and descriptor chains. Every field provided by the guest, including queue indices, buffer addresses, descriptor flags, and transfer lengths, is untrusted input. The VMM must check this input before proceeding with host-side privileges. CVE-2026-5747 was related to handling virtio PCI queue configuration. VENOM involved floppy controller register emulation. The attack method remains the same: the guest writes something that the VMM fails to validate correctly.
Xen's architecture introduces a completely different approach. Instead of emulating devices, zones communicate with the host using shared memory and structured messages. Here’s how it works:
- The zone and dom0 share a memory page, set up through the Xen grant table mechanism. The hypervisor manages this sharing; neither domain can access the other's memory without a specific grant
- The zone writes a structured IDM message to a ring buffer in that shared page
- The zone sends a lightweight inter-domain interrupt through a Xen event channel to inform dom0 that a message is ready
- The Edera daemon on dom0 reads the ring buffer, decodes the protobuf-encoded IDM message, and takes action
- The daemon writes back a response and signals via the event channel
There's no register emulation, no MMIO traps, no VMEXIT for each register write, and no device state machine. The guest is not communicating with a system that mimics a NIC or a disk controller. Instead, it exchanges typed messages with a daemon through a shared memory channel.
This difference is not just a "smaller surface." It represents a fundamentally different type of surface.
.png)
The ls /dev/xen/ command inside a zone shows the plumbing: evtchn (event channels), gntalloc/gntdev (grant table), xenbus (configuration exchange). These are communication tools, not emulated hardware. There is no virtual NIC, no virtual disk controller, and no virtual anything. The zone's I/O goes through structured messages, not through a process pretending to be a device.
This is why CVE-2026-5747 is not a vulnerability class for this architecture. The same applies to VENOM, any QEMU CVE, and any future device emulation bug in any VMM. That attack surface does not exist.
Honest Trade-offs: What This Architecture Costs
Architecture alone does not determine security outcomes. Edera's model has real trade-offs, and recognizing them is important.
Xen has a history of CVEs. Xen Security Advisories (XSAs) related to grant tables, event channels, and memory management have been genuine vulnerabilities. The hypervisor is written in C, so it is vulnerable to the same classes of bugs that affect VMMs. However, the Xen hypervisor has a smaller and more closely examined code base than any combination of VMM and kernel. It is also the only trusted component since there is no additional VMM layer to heighten the risk.
KVM offers better features for confidential computing. AMD SEV-SNP, Intel TDX, and Arm CCA are KVM-native technologies that encrypt VM memory, securing workloads even when the hypervisor is compromised. Xen has some support in this area, but it is less advanced. If your threat model includes a compromised hypervisor, KVM-based solutions offer some advantages.
Ecosystem maturity varies. Firecracker powers Lambda and Fargate. Kata has years of production deployments across multiple clouds. gVisor runs in GKE. Edera is newer. An independent audit by Trail of Bits (2025) found no high or medium-severity vulnerabilities in the zone boundary. Our own recent full-source audit confirms that the daemon's Rust code is well-protected at the zone-to-host trust boundary. But production experience matters, and newer systems have less of it.
Vulnpocalypse Readiness: Rating Every Major Container Isolation Model
We reviewed Edera's full source. We examined the public security records of every major container isolation solution. We assessed each one based on four important criteria when AI is hunting for bugs: what enforces the security boundary, how much exploitable surface exists, how well privileged components are separated from the host, and whether secure configuration is mandatory or optional.
We evaluated six isolation models across five criteria: isolation boundary type, exploitable attack surface, disaggregation quality, configuration enforcement, and readiness for AI-assisted threat discovery:
.png)
Pay close attention to the rightmost column. There is exactly one "A" in this table, and it isn't because Edera's engineers are smarter than Firecracker's or because Xen is special. It is because Edera is the only architecture in the list without that attack surface where AI is currently finding bugs. Every other solution has some code – a VMM, a syscall interceptor, a kernel module, or a device emulator – placed between untrusted workloads and trusted host privileges. AI-assisted vulnerability discovery turns that code into a ticking clock.
Three Questions That Matter More Than Benchmarks
If you are choosing a container isolation solution, three questions matter more than benchmarks:
1. What is the actual isolation boundary?
Namespaces do not serve as a boundary. A shared kernel with seccomp filters is a mitigation, not true isolation. Hardware-enforced memory partitioning—via a hypervisor, be it Type-1 or Type-2—is the minimum for workloads that handle untrusted input, run multi-tenant services, or manage sensitive data.
2. What runs between the boundary and your workload?
The hypervisor provides the boundary. The VMM is in between it and the guest. Every line of VMM code that processes guest-controlled input represents attack surface. The less VMM code, the better. No VMM code is best.
3. Does the default configuration enforce the security model?
A solution that allows operators to accidentally deploy with QEMU, disable isolation for certain workloads, or run with a privileged flag that bypasses the boundary will eventually be deployed that way. Security properties requiring correct configuration are security properties likely to be missing in production.
The Patching Treadmill Has No Exit: What Operators Should Do Now
CVE-2026-5747 is not a crisis. AWS patched it before disclosure. No services were affected. Firecracker's security team and Anthropic's researchers handled it responsibly. We expect this entire process to become routine over the next year. That is exactly the issue.
The container isolation industry has spent a decade shrinking attack surfaces – smaller VMMs,fewer emulated devices, tighter syscall filters. This was the right strategy when the constraint was human attention. A smaller surface meant fewer places a researcher could find a bug within a finite audit budget. It is the wrong strategy when the constraint is no longer human attention.
Frontier AI can thoroughly audit a 50,000-line Rust codebase in hours. It can navigate every state machine, probe every register interaction, model every queue handoff. The "audit budget" is now whatever a cloud provider pays for compute. Every interface exposed to untrusted input will be thoroughly explored in days or weeks by capabilities that enhance every quarter. If your architecture requires a VMM, that VMM will contain bugs, and those bugs will be found faster than they can be fixed.
When the constraints change, the strategy must change. The container isolation solutions that will endure the vulnpocalypse are the ones that eliminate attack surface entirely, not those that just keep making it smaller.
Xen vs KVM: What Edera's Two Deployment Models Actually Provide
The rating table above has one "A." That rating reflects a specific architecture: Edera on Xen, where there is no VMM, no device emulation, and no virtio. The attack surface for CVE-2026-5747 and its entire vulnerability class does not exist.
We are also bringing KVM support to Edera, because our customers need it. Some organizations have deployment constraints, compliance requirements, or infrastructure that makes KVM the right choice for their environment. That is a legitimate engineering decision, and we’re meeting our users where they are.
But we want to be honest about what that means.
KVM needs a user-space VMM. That means host-side software must handle VM exits and service guest requests, often by emulating devices or other privileged interfaces, which is the exact attack surface this post discusses. We will apply our containment philosophy to that implementation. However, a VMM comes with trade-offs that Xen does not have. While Edera on KVM will not offer the same security features as Edera on Xen, we plan to evolve the platform in a direction which aligns with the same direction as Edera on Xen. We will clearly explain what each deployment model provides and what it costs.
This is the same calculus the industry makes every day. Kubernetes creates a large attack surface and operational burden, but for most organizations, the benefits outweigh the costs. KVM is a similar choice. The best hypervisor for you depends on your threat model and deployment needs, not ours.
If your workloads need the strongest possible isolation boundary – no VMM, no device emulation, no shared kernel – Edera on Xen removes attack surfaces that no KVM-based solution can. If your environment requires KVM, we will provide a deployment that aligns with our security principles and we will honestly explain how it compares.
Every other solution in the table – standard containers, gVisor, Kata with any VMM, standalone Firecracker – has exploitable surfaces that AI is actively finding and will keep finding. Firecracker has patched CVE-2026-5747 and will address the next vulnerability and the next one after that, but the design guarantees there will always be a next one. If your current solution falls in the B or C tier and you want to understand what migration looks like, we’d like to talk.
-3.avif)