
User Namespaces Are Not a Security Boundary
There's a thing that happens in our industry where a mechanism designed to solve one problem gets marketed as a solution to a completely different problem. User namespaces are the latest example. User namespaces trade UID isolation for kernel attack surface.
User namespaces were added to the Linux kernel to allow unprivileged users to perform operations that normally require root.
Read that sentence again, slowly.
We built a mechanism whose explicit purpose is to give root-equivalent capabilities to non-root users. If you read that sentence and your first reaction was "what could possibly go wrong," you're not alone.
The canonical use case for user namespaces is allowing a build system to call mount() inside a container without granting actual host-level capabilities. That's a reasonable feature. What’s less reasonable is selling it as a multi-tenancy isolation boundary. Sysbox and vNode (often used with vCluster) depend on user namespaces for isolation. The pitch sounds compelling: each tenant runs as an unprivileged user on the host, but gets root-like capabilities inside their own namespace. Isolation without virtualization overhead.
We tested user namespaces and the results are eye-opening.
What User Namespaces Do to The Kernel Attack Surface
The Kubernetes documentation describes user namespaces this way:
A process running as root in a container can run as a different (non-root) user in the host; in other words, the process has full privileges for operations inside the user namespace, but is unprivileged for operations outside the namespace.
It is expected user namespace will mitigate some future vulnerabilities too.
That last sentence is worth examining.
When a process calls unshare(CLONE_NEWUSER), it creates a new user namespace and receives a full set of capabilities inside it: CAP_SYS_ADMIN, CAP_NET_ADMIN, CAP_SYS_CHROOT, the works. The documentation is correct that these capabilities don't grant host-level privileges. And it's true that for certain classes of vulnerabilities, particularly those that depend on running as host root, remapping UID 0 to an unprivileged host user is a meaningful defense.
But this framing omits the other side of the story. Those scoped root capabilities invoke host kernel code that is not scoped at all. CAP_NET_ADMIN inside a user+network namespace means you can open a NETLINK_NETFILTER socket and interact directly with nftables. CAP_SYS_ADMIN inside a user+mount namespace means you can mount tmpfs, overlayfs, devpts, and other filesystems. The capabilities are namespaced, but the kernel code they expose to an untrusted container is the same nftables, overlayfs, networking stack that runs in ring 0 on the shared host kernel.
The Kubernetes documentation expects user namespaces to mitigate future vulnerabilities but our data suggests they are likely to enable others. We found forty CVEs over the span of five years, eighteen in nf_tables alone, that are only reachable when user namespaces are enabled.
User namespaces aren’t a panacea. They don't isolate you from the shared kernel, they give you a welcome mat at the door.
Why Shared Kernel Risk Makes User Namespaces Dangerous in Multi-Tenancy
Every operation a container performs, reading a file, sending a packet, allocating memory, etc. ends up as a request to the kernel. The kernel executes that request in ring 0 context, with full access to every byte of memory on the machine (including every other container's memory and host credentials.)
This is working as intended, normally. The kernel is designed to handle requests from unprivileged processes safely. But "safely" only holds as long as the code handling those requests is bug-free. When a kernel subsystem has a vulnerability such as a use-after-free, a buffer overflow, or a race condition, any process that can reach that code can potentially exploit the kernel and take over the entire machine. This includes every secret, every workload, and every tenant.
This is why the kernel restricts which code paths unprivileged processes can reach. If you’ve ever seen EPERM errors on a system, that’s the kernel saying you don’t need access to that code, so you don't get access to it. That restriction of kernel surface is one of the most important things standing between a compromised container and a compromised host.
User namespaces remove those restrictions.
In a multi-tenant environment, user namespaces enable every tenant on the shared kernel to reach the same complex subsystems. When one of those subsystems has a vulnerability, it's not one tenant's problem, it's every tenant's problem. The tenant running your AI inference workload and the tenant running your customer's billing system share a kernel, and user namespaces just gave both of them access to the same 300,000 lines of nf_tables C code. That's not multi-tenancy. That's a shared attack surface behind a login page.
Measuring the Attack Surface: 262% More Kernel Operations Reachable
We built a tool that systematically probes which kernel operations are reachable with and without user namespaces. We ran it from inside an unprivileged container on an EKS cluster running kernel 6.18.
Without user namespaces: an unprivileged container process could reach 8 out of 40 tested kernel operations.
With user namespaces: the same process could reach 27 out of 40.
That's 21 newly reachable kernel operations, or a 262% increase in attack surface.
The following results were captured from an unprivileged container on an Amazon EKS cluster running Linux kernel 6.18, testing 40 kernel operations with and without user namespaces enabled:
PROBE BASELINE USERNS DELTA
unshare(NEWUSER) OK EPERM ---
unshare(NEWNET) EPERM OK NEW
unshare(NEWNS) EPERM OK NEW
unshare(NEWPID) EPERM OK NEW
mount(tmpfs) EPERM OK NEW
mount(overlay) EPERM ENOENT NEW
mount(devpts) EPERM OK NEW
socket(RAW) EPERM OK NEW
socket(PACKET) EPERM OK NEW
create_veth EPERM OK NEW
create_bridge EPERM OK NEW
nft_new_table EPERM EINVAL NEW
nft_new_chain EPERM EINVAL NEW
chroot() EPERM OK NEW
bpf(PROG_LOAD) EPERM EPERM neither
mknod(char) EPERM EPERM neitherEvery NEW entry is code paths enabled only thanks to user namespaces being enabled. Note: nftables reads EINVAL (invalid argument) which means the kernel entered the nf_tables subsystem and got far enough to validate the message format. That's the entire attack surface that CVE-2024-1086 and CVE-2023-32233 exploited.
What an Unprivileged Container Can Do Inside a User Namespace
Numbers are abstract so let me show you what an unprivileged container can actually do once it creates a user namespace.
Create 20 Types of Network Devices
From inside a user+net namespace, we attempted to create 20 different types of virtual network devices. Every single one either succeeded or reached the driver-specific kernel code. Zero requests were blocked.
Devices fully created: dummy, bridge, veth, bond, team, wireguard, ifb, vcan, vxcan. Devices with code path reached: macvlan, ipvlan, vxlan, geneve, gretap, ipip, sit, vrf, xfrm, bareudp, netdevsim.
Each device type invokes a separate kernel module. Creating these devices caused the kernel to auto-load 15+ kernel modules from an unprivileged container. Every loaded kernel module expands the attack surface for every container on the host.
Run a Full Firewall
From the same unprivileged container, we installed nft and created a complete firewall ruleset: tables, chains hooked into the kernel packet path, rules with connection tracking. All created by an unprivileged container.
We then stress-tested the nf_tables subsystem from that same namespace. The kernel didn’t crash, which means Amazon's patches are working but every one of those operations is kernel code that an unprivileged process should never be touching.
Mount Filesystems
From a user+mount namespace: tmpfs, devpts, ramfs, bind mounts, and overlayfs all succeeded or reached the kernel's filesystem code. These are the same code paths where CVE-2022-0185 (heap buffer overflow in fsconfig) and CVE-2023-2640 (Ubuntu overlayfs privilege escalation) lived. Ubuntu’s guidance, “If not needed, disable the ability for unprivileged users to create namespaces.”
40 Linux Kernel CVEs in 5 Years
Our testing shows that user namespaces expose vast amounts of kernel code. But you don't have to take our word for the security implications of this, the CVE database highlights the problem.
We cataloged 40+ Linux kernel CVEs from 2020 to 2025 where user namespaces were a prerequisite for exploitation or substantially lowered the exploitation barrier. The data is not subtle:
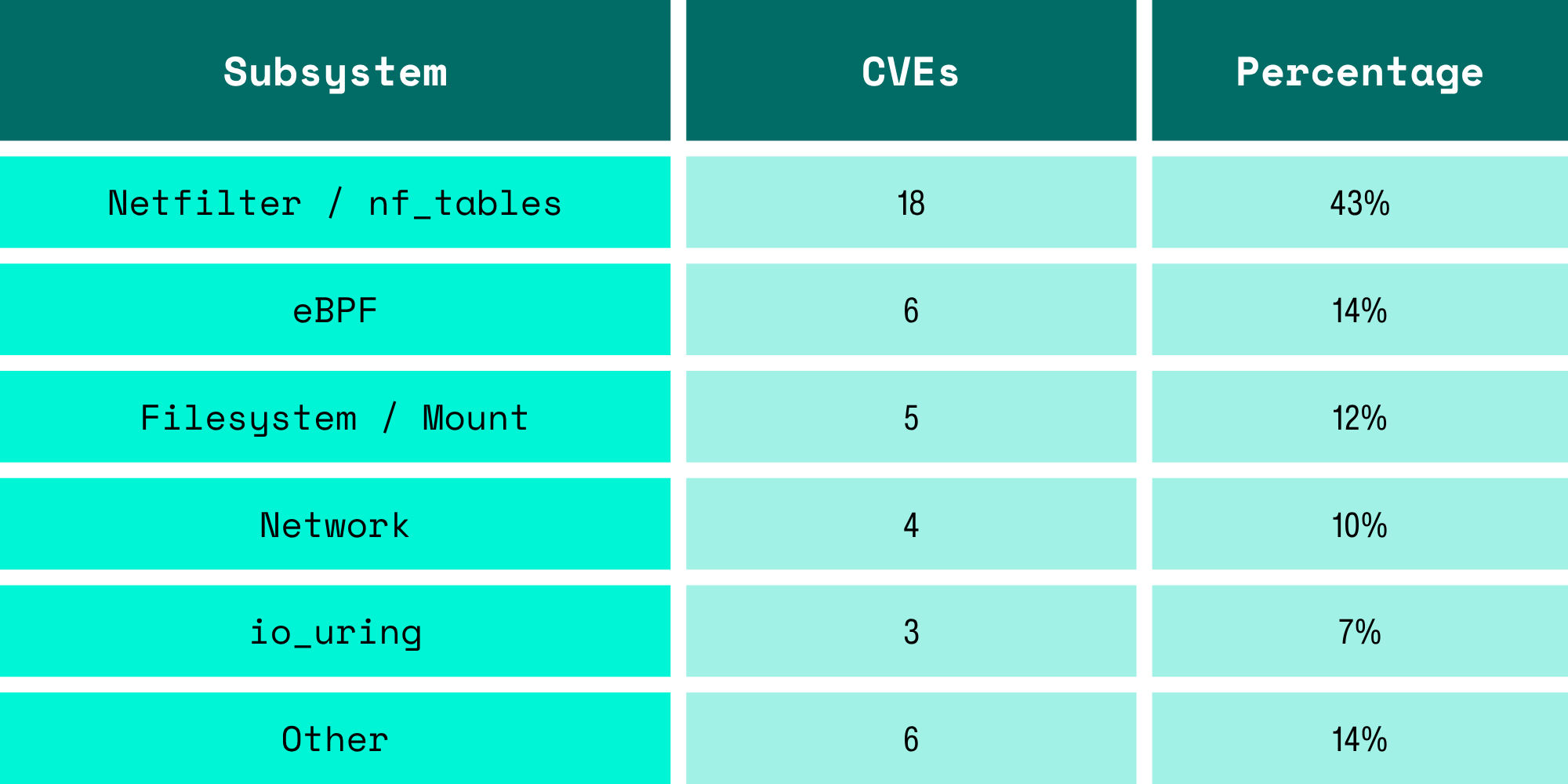
Forty-three percent of all user-namespace-gated CVEs are in a single subsystem: nf_tables. This is a consequence of exposing complex, actively-developed kernel code to unprivileged users.
The exploitation pattern for nearly every nf_tables CVE is identical:
1. unshare(CLONE_NEWUSER | CLONE_NEWNET) // create namespace
2. Map UID 0 in new namespace // gain CAP_NET_ADMIN
3. Open NETLINK_NETFILTER socket // permitted in namespace
4. Send crafted nf_tables packet // trigger kernel bug
5. Corrupt kernel memory // Container escape
Without user namespaces enabled, the kernel blocks access to the subsystem, step 3 returns EPERM and the entire attack chain is mitigated. User namespaces are the key that unlocks it.
Security researchers discovered the user namespace to nf_tables attack surface around 2021-2022, and the bug density has been high enough to sustain a continuous stream of CVEs ever since:
- 2021: 1 netfilter CVE
- 2022: 5 netfilter CVEs
- 2023: 8 netfilter CVEs
- 2024: 4 netfilter CVEs (ongoing despite years of scrutiny)
These aren't obscure bugs. CVE-2024-1086, a double-free in nf_tables verdict handling, achieved a 99.4% reliable exploitation rate for container escape and the exploit code has been published to Github with 2.4k stars. CVE-2022-0185, a heap overflow in fsconfig, was used in the wild in real-world Kubernetes container escapes. CVE-2023-32233, a use-after-free in anonymous set handling, had public exploits within days of announcement.
Every CVE required user namespaces. Every one of them was reachable from an unprivileged container.
Don’t take our word for it: What Linux Distributions and Docker Say About User Namespaces
User namespaces improve security by allowing containers to run as non-root. That’s a valid position. But also: user namespaces allow unprivileged processes to reach kernel code that was previously restricted to root. Whether you frame that as a security improvement depends entirely on whether you think the kernel code is bug-free. Forty CVEs in 5 years say it's not.
Debian and Ubuntu recognized this years ago and added a sysctl (kernel.unprivileged_userns_clone) to disable unprivileged user namespace creation entirely. Docker's default seccomp profile blocks unshare(CLONE_NEWUSER) since version 20.10. Ubuntu 24.04 added AppArmor-based user namespace restrictions. The distributions that deal most directly with real-world security are systematically limiting user namespaces, even as projects built on top of them market user namespaces as a security feature.
When kernel maintainers are adding knobs to turn off a feature, and the projects built on that feature are marketing it as a security boundary, there’s a mismatch and the CVE data above tells the story.
What to Use Instead of User Namespaces for Tenant Isolation
If user namespaces aren't a security boundary, what is?
You need a real boundary. Not a permission check in a shared codebase, but an architectural boundary that survives the codebase having bugs.
User namespaces solve a real problem: letting unprivileged processes perform privileged operations in a controlled context but they are not an isolation boundary. They are a mechanism that exposes complex, bug-prone kernel code to every unprivileged process that can call unshare. Using them as a multi-tenancy primitive is building your security architecture on 300,000 lines of C that has produced 18 CVEs in 5 years, and counting.
And the rate is about to accelerate.
The vuln-pocalypse: AI-Assisted Vulnerability Research Is Accelerating the Threat
Every CVE in our dataset was found by skilled security researchers: people who understand nf_tables internals, who can read kernel code fluently, who spent weeks (or months) manually auditing code paths. Finding kernel bugs has historically been hard, which has kept vulnerabilities manageable, and has kept anyone with a threat model that excludes nation-states and well-funded adversaries safe.
That reality is changing. Nicholas Carlini, a researcher at Anthropic, recently demonstrated Claude code discovered a previously unknown critical vulnerability in Ghost (a project with 50,000+ GitHub stars) in approximately 90 minutes. In the same presentation, he showed the model identifying remotely exploitable heap buffer overflows in the Linux kernel.
The nftables codebase hasn't gotten simpler, the attack surface hasn't shrunk. We are approaching a world where finding a use-after-free in nf_tables doesn't require years of kernel hacking expertise. It requires a Claude Max subscription and a free weekend. The 40 CVEs in our dataset were found over five years by dozens of specialists. The next 40 CVEs will not take five years.
User namespaces are the mechanism that makes those bugs reachable from an unprivileged container. Projects that are betting on user namespaces for isolation are betting that kernel bugs will be found and patched faster than they are discovered and exploited. That bet has been getting harder every year. And with AI-assisted vulnerability research, it's about to get a lot worse.
How to Audit and Reduce User Namespace Exposure Today
User namespaces are useful. They reduce the impact of certain classes of vulnerabilities by removing host-root equivalence. In a single-tenant environment, that tradeoff might work.
In a multi-tenant environment, the math is different. You’re trading reduced blast radius for some bugs in exchange for 262% more kernel attack surface shared across every tenant on the node. Forty CVEs in five years says that attack surface is not theoretical.
Here is what I recommend you do.
Audit your exposure right now: Check max_user_namespaces on Every Node
cat /proc/sys/user/max_user_namespacesIf the number is greater than zero, unprivileged user namespace creation is enabled. Every container on that node can reach the nf_tables, overlayfs, and networking subsystems tested in this piece.
Check whether any workloads depend on user namespaces:
# Count processes in non-init user namespaces
find /proc/*/ns/user -exec readlink {} \; 2>/dev/null | sort | uniq -c | sort -rn
If the only user namespace is the init namespace, you can disable unprivileged creation without breaking anything:
sysctl -w kernel.unprivileged_userns_clone=0Stop treating user namespaces as a tenancy boundary
If you are using sysbox, vCluster with vNode, or any product that depends on user namespaces for tenant isolation: understand what you are buying. You are getting UID remapping, not kernel isolation. Every tenant shares the same nf_tables, the same overlayfs, the same networking stack. A kernel bug in any of those subsystems is a bug in every tenant's environment simultaneously.
This is not a configuration you can fix, it’s the architecture. If your threat model includes tenant-to-tenant isolation, user namespaces are not sufficient. They were never designed to be.
-3.avif)