NUMA Part 1: Cores, memory, and the distance between them
Two virtual machines on the same host, configured identically, running the same workload. One of them is 20% slower than the other, consistently. Nothing is wrong with the workload, nothing is wrong with the host, no contention from other tenants. The slow one's memory just happens to be on the wrong side of an interconnect from the CPUs running it, and there is no in-guest knob the operator can turn to fix it.
That is the story this series is about. Edera shipped a stack of changes that make Xen-based virtualisation NUMA-aware end to end - inside the guest, through the paravirtual I/O drivers, into dom0, and back to the hypervisor's view of host hardware. Some of those pieces are, as far as we can tell, the first implementations anywhere. To explain why any of it matters, we have to start with what NUMA actually is.
Where NUMA came from: From UMA to Multi-Socket Servers
NUMA stands for Non-Uniform Memory Access. The defining property is in the name: memory access cost on a NUMA machine is not uniform. Which CPU is doing the access matters, and which physical memory bank the data lives in matters, and the cost depends on the relationship between those two things.
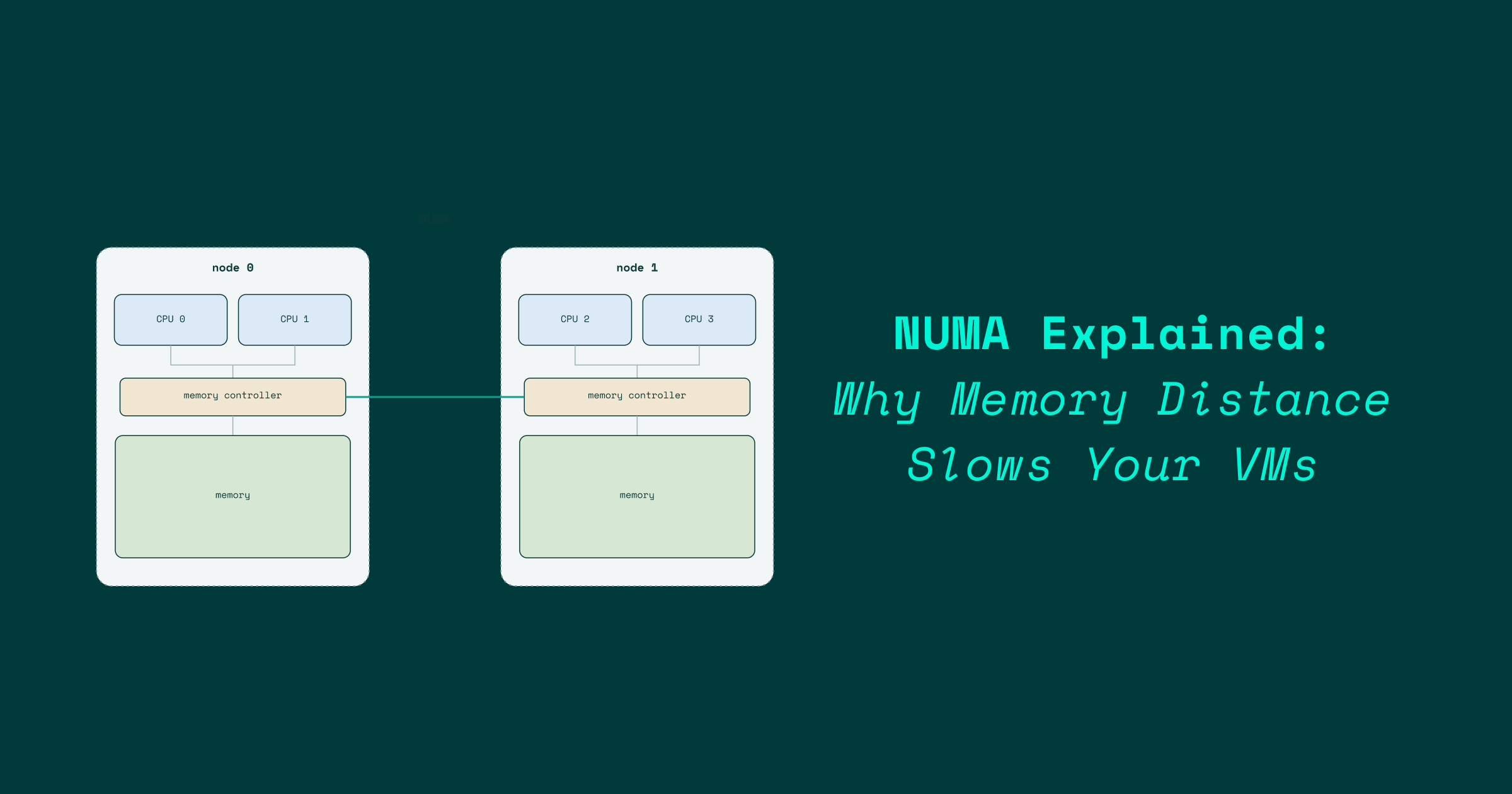
The historical opposite of NUMA is UMA, Uniform Memory Access, where every CPU reaches every byte of memory through the same memory controller at the same cost. UMA was the world of single-socket commodity servers and many embedded systems. It is conceptually simple and it scales up to a limit - that limit being roughly "as many cores as you can fit on one chunk of silicon with one set of memory channels".
What happens when you need to push past that limit? UMA scales until it stops, and "stops" has a few intertwined reasons. Electrical trace lengths get long. Signals take longer to propagate end to end, and at the data rates a modern memory bus runs at, longer traces also force you to slow the bus down to keep signal integrity - which piles latency on top of latency. (This is the same physics behind the L1 / L2 / L3 cache hierarchy: L1 is small partly because keeping a cache small and physically close to the core is what keeps it fast.) A single memory controller cannot feed an arbitrary number of cores at full bandwidth; pin counts on the package put a hard ceiling on how many memory channels you can wire to one socket. Bus contention between many CPUs trying to read memory simultaneously stops being negligible. The industry's answer was to give each socket (or die) its own memory controller and stop pretending memory is one symmetric pool. The machine becomes NUMA. Each node has its own CPUs and its own slice of memory; CPUs can still read from any node, but reads to a remote node have to cross an interconnect, and the interconnect is fast in absolute terms and slow relative to a local DRAM access.
It helps to think of the interconnect as a bridge between two adjacent towns. On an empty road, the crossing is only marginally slower than local traffic; at rush hour, when everyone is trying to use the same bridge at once, the cost is whatever the queue happens to be. We will come back to that distinction when we talk about how NUMA looks on a busy production workload versus a quiet microbenchmark.
A short chronology to anchor where this came from. Commercial NUMA showed up in the 1990s in big-iron systems aimed at a small set of buyers who needed more cores than one bus could feed: SGI's Origin line, Sequent NUMA-Q, Compaq's AlphaServer GS series, all with bespoke node-to-node fabrics. NUMA arrived in commodity x86 in 2003 with AMD's Opteron, which gave each socket its own memory controller and connected sockets via HyperTransport. Intel caught up in 2008 with Nehalem and the QuickPath Interconnect (QPI), after a long run of front-side-bus chipsets that were genuinely UMA (all CPUs sharing one bus to a northbridge, no per-socket memory at all). Today's Intel parts use the Ultra Path Interconnect (UPI), the descendant of QPI; today's AMD parts use Infinity Fabric, the descendant of HyperTransport. Each generation lifted the absolute bandwidth substantially, but the ratio of remote-to-local DRAM cost has stayed stubbornly in roughly the same range.
You might be tempted to think, looking at all of this so far, that each socket is one NUMA node and be done with it. For most of the decade after Opteron, that was right. Operators learned NUMA as "the topology mirrors the sockets" because at the per-socket core counts of the era a single memory controller could feed the whole socket without trouble. The mental model worked.
That stopped being true around the late 2010s. AMD's Zen-based EPYC pushed per-socket core counts high enough - and made the manufacturing tradeoffs of one giant monolithic die unattractive enough - that the package moved to a small constellation of chiplets: several Core Complex Dies (CCDs) inside one socket, each with its own slice of L3 cache and its own slice of the memory controller, glued together by Infinity Fabric. The wrinkle is that Infinity Fabric is now used inside a socket between CCDs, not just between sockets: it is the same fabric, doing the same job, at a smaller scale. A single EPYC socket can therefore present several NUMA nodes to the OS, depending on the part and the BIOS configuration - the "Nodes Per Socket" (NPS) knob, NPS1 through NPS4 on current generations.
Intel's version of the same idea is Sub-NUMA Clustering (SNC). Off by default but available in BIOS on recent Xeon parts, SNC partitions the on-die mesh of memory controllers and presents the result as multiple NUMA nodes per socket.
"One socket, one node" was a useful first approximation, and it stopped being correct on commodity hardware a few years ago. Greater-than-two-socket x86 servers have become rare outside specialized niches; the interesting NUMA complexity on modern systems comes from inside a single dual-socket box, where four to eight nodes is now routine.
How big is "slow"?
A precise number is platform-specific and people argue about the precise methodology, but a useful rule of thumb is that a remote DRAM access on a modern server costs roughly 1.5x to 3x what a local one costs. The bandwidth is also lower, sometimes by a similar ratio. Those numbers are what you measure with a microbenchmark on an idle machine.
On a real workload, the gap is usually worse, because the interconnect is shared. If many cores are doing cross-node accesses at once, they contend for the same interconnect bandwidth, so per-request latency goes up. This is the mechanism behind a lot of "why is this server slow at high load" mysteries. The microbenchmark says cross-node is 2x worse. The production workload sees 4x or 5x worse because everyone is fighting over the same pipe.
The corollary is worth mentioning: NUMA effects do not just slow the affected workloads down, they make their performance less predictable. The same request can take 80 nanoseconds or 250 nanoseconds depending on what else is on the interconnect at the moment. Average latency is a useful number but tail latency is where NUMA pain usually first shows up.
Interleaving: sacrificing peaks for floors
There is a well-known way to flatten the cost curve without doing any of the work to understand where memory should live: memory interleaving. Allocate pages round-robin across all nodes, regardless of which node the requesting task is on. On Linux this is numactl --interleave=all; some databases and JVMs do something equivalent in their own allocators; a few hypervisors do it implicitly for guest memory when they have nothing smarter to fall back on.
A BIOS-level version of the same idea exists too. Most dual-socket server firmwares have a "Node Interleaving" or "Memory Interleaving Across Nodes" toggle that spreads physical memory across the sockets at cache-line or page granularity. With it on, the OS sees one big UMA pool instead of a NUMA topology, and whatever NUMA-aware code it has becomes inert: there is no topology left to be aware of.
That toggle is most common on dual-socket boxes, but the deeper problem is the same everywhere: interleaving scales badly. The more nodes you have, the longer the worst-case path between any core and any memory bank gets, and the more pressure the interconnect comes under to carry all that round-robin traffic. The trade interleaving makes - predictable mediocrity over unpredictable mix - only gets steeper as the topology widens.
Interleaving makes the expected cost of any single allocation roughly equal to the average of all the node-to-node costs on the machine. On a two-node host, that means about half your accesses are local and about half are remote, by construction. Latency variance collapses, because the workload no longer wins or loses based on which page it happens to touch.
A former colleague had the cleanest one-line summary of this trade: interleaving makes everything equally bad. It is consistency at the cost of peak. A workload that could have fit entirely on a single node, hitting only local memory, is now paying remote-access cost on half its allocations every time.
This is a real tool and there are real reasons to reach for it. NUMA-oblivious software running on a NUMA host gets predictable performance from interleaving, and "predictably bad" is often easier to operate than "unpredictably mixed". Memory-bandwidth-bound workloads that span the whole machine anyway can even come out ahead, because they get to aggregate the bandwidth of every memory controller instead of saturating one.
But it leaves a lot on the table. A workload that does know its own access pattern, running on a stack that gives it correct topology and honours its placement requests, can do substantially better than interleaving on both latency and throughput. The whole point of the work this series is about is that the Xen guest no longer has to pick between "blind and hope" and "blind and interleave". The guest can know where it is, and then act on it.
Two affinities, not one
A lot of developers go their whole careers without thinking about NUMA. If your deploy target has been laptops, single-socket workstations, or the kind of cloud VM that has been carved out of a single host node, you have effectively been on a UMA machine the whole time, and NUMA-aware tooling has lived at the periphery of your view at best. It shows up the day the workload moves onto a bigger box, usually with no warning louder than "this is weirdly slow", and the standard developer reaction is to discover an entire second axis of placement that nobody mentioned.
The first axis, the familiar one: if you have ever pinned a process to specific CPUs with taskset or sched_setaffinity, you already know one half of the picture. Tasks have an affinity for CPUs. The kernel scheduler tries to keep them where you put them. CPU affinity is the half that tends to show up in tutorials and blog posts.
The other half is memory affinity, and it comes up far less often. On Linux it is controlled through mbind(), set_mempolicy(), and the libnuma helpers like numa_alloc_onnode(), all of which decide which NUMA node an allocation comes from; the numactl(8) man page is the practical entry point. The kernel also does automatic NUMA balancing of its own - the NUMA_BALANCING knob - migrating pages toward whichever CPU keeps touching them.
The default Linux behaviour around memory placement is worth knowing because it bites people. It is called "first touch". When userspace asks for a page - via malloc(), mmap(), anything that boils down to a page fault - the page is not actually allocated immediately. It is allocated the first time some CPU touches it. The node the page lands on is whichever node the touching CPU was on, not whichever node the requesting CPU was on if those differ. That is fine for a process that allocates and uses its memory from the same thread. It is a quiet disaster for a common pattern: one initialisation thread allocates and zeroes a big buffer, then worker threads on other nodes consume it. Every page lands on the initialiser's node; every worker access is remote; the operator sees "this benchmark is slower than it should be and I cannot figure out why".
The collision between CPU affinity and memory affinity is where most of the interesting behaviour happens. They have to agree for the optimization to work. If your task is pinned to node 0 and its memory is on node 1, you have done worse than not pinning at all - you have guaranteed every access is remote. Conversely, if you allocated memory on node 0 but your task gets scheduled to node 1, same outcome. First-touch is one specific way the two end up disagreeing without the operator noticing.
Three things can cause a remote NUMA access:
- the task is running on the wrong CPU relative to its data,
- the data is sitting in the wrong memory bank relative to the task,
- or both.
Plain Linux gives userspace the tools to handle all of this for processes you control. The harder questions are the ones one layer up: what does the OS itself know about the topology, who exposes that information to whom, and what happens when one of the layers goes blind?
What the OS sees - and what Xen’s dom0 misses
A NUMA-aware kernel does more than know there is a topology. It divides the physical memory map into per-node chunks and tracks which CPUs are local to each, then exposes that information to userspace. numastat, numactl -H, and the /sys/devices/system/node/ hierarchy are the visible ends of that machinery: a userspace process can ask "how much free memory is on node 0?" or "which CPUs are local to the memory I just allocated?" and get a real answer. The underlying source of truth is the firmware's System Resource Affinity Table (SRAT) and System Locality Information Table (SLIT), both of which we will run into again later in this series.
The same machinery is also where another surprise lives. Historical "one socket, one node" boxes had generous per-node memory: a dual-socket server with 256 GiB had two 128 GiB nodes, and "fit your workload in a node" was easy. Multi-node sockets break that intuition fast. Take the same dual-socket box, populate it with EPYC parts, set the firmware to NPS4: four nodes per socket, eight nodes per host, 32 GiB per node. A workload that used to be obviously single-node can suddenly need two or three nodes purely because of the per-node DRAM math, even if its CPU footprint fits on one node easily. The arithmetic is unforgiving and it surprises people the first time they hit it.
It is worth being concrete about the layers of awareness involved here, because the cost of getting it wrong depends on which layer is the one that does not know:
- A NUMA-aware application on a NUMA-aware kernel, on NUMA hardware. The design point everyone has been aiming at since the 1990s: latency is low, variance is low, and the application can tune itself if it cares to.
- A NUMA-oblivious application on a NUMA-aware kernel. The common case in practice. The kernel does best-effort balancing on the application's behalf, so the application gets close to the same average performance - just with more variance and some headroom left on the table.
- A NUMA-oblivious application on a NUMA-oblivious kernel. Everything falls back to "wherever the allocator happened to put it". The kernel cannot expose information it does not have, no userspace tool can ask a question that has no answer, and any application that wanted to be NUMA-aware is out of luck.
That last case is the worst place to be, and - perhaps surprisingly - it is exactly where you land the moment you stack two of these stacks on top of each other. Upstream Xen's dom0 has been sitting in that corner since forever. It is a privileged guest on a NUMA host, but Xen gives it no NUMA topology at all - one undifferentiated machine, no matter how many nodes the hardware really has. That is not just an aesthetic gap: dom0's memory sits on the host's physical nodes and its vCPUs on the host's CPUs, but with no topology to consult, a storage daemon or container runtime in dom0 cannot tell a local page from a remote one - so a steady fraction of its accesses cross the interconnect unseen, while numactl -H inside dom0 reports one tidy node and nothing in it knows to care. Which makes virtualisation the next thing to talk about.
Two stacks, each seeing half
A normal Linux machine has one kernel, one scheduler, and one memory allocator. They share state. When they make placement decisions they at least have the option to coordinate.
A virtualised system has two of each, stacked. The hypervisor allocates host memory and pins or floats vCPUs. The guest kernel allocates guest memory and schedules its own threads onto its vCPUs. The two stacks are trying to make the same kinds of decisions about the same physical resources, but each one only sees half of the picture.
How that mismatch plays out depends on what sits underneath the hypervisor. On KVM there is a whole Linux kernel down there: a VM is just a qemu process, and the host kernel's scheduler, page allocator, and NUMA balancer treat it like any other process, so most of the NUMA machinery already applies to it for free. On Xen, ESXi, or the Hyper-V parent partition there is no underlying OS - the hypervisor drives the hardware directly, and if it does not understand NUMA, nothing on the host does.
That distinction is load-bearing for this series. On KVM, the host Linux already knows about NUMA, and most of the relevant infrastructure - numactl on the qemu process, cgroup CPU pinning, automatic NUMA balancing - works out of the box without anyone having to build something new. On Xen, the privileged management guest is conventionally called dom0 ("domain zero") - it owns the physical device drivers and the toolstack that launches every other guest. Any unprivileged guest is conventionally called a domU ("domain U", for unprivileged); the rest of this series uses the two terms freely. Dom0 is itself a guest of the hypervisor, and the hypervisor below it has to make these placement decisions on its own behalf. A lot of what this series is about is Xen catching up to that baseline, and in places going past it.
The flip side of "KVM gets it for free" is worth careful consideration too: letting an autonomous host-side scheduler balance NUMA across many tenants is exactly the kind of "smart" behaviour that produces "noisy neighbour" problems. VM A's memory migrates because VM B's placement changed, and now VM A's tail latency wobbles for reasons VM A cannot see. Explicit placement decisions made by a control plane, before the workload starts, dodge that class of problem - but only if the control plane has accurate topology to make decisions from. Which brings us back to the original two-stack mismatch, one level out.
On Xen specifically, that mismatch shows up as three separate decisions about a guest's NUMA experience, none of which the guest itself gets to make:
- Where does a guest's memory live on the host? The toolstack picks at launch time and the hypervisor honours the placement. The guest learns what was decided by reading its vNUMA topology if it has one; the guest does not get a vote in the matter.
- Where do a guest's vCPUs run on the host? The hypervisor's scheduler picks. Or, if vCPUs are pinned, an operator picked at boot time.
- What does the guest think the topology is? If you do nothing, the guest sees a single uniform address space, no matter how its memory and vCPUs are actually spread across the host. numactl -H inside the guest shows one flat node where the host might have eight, and the guest's own NUMA-aware code has nothing real to act on.
Item 3 is the one that bites hardest, because it turns the guest's own optimisations against it. The hypervisor may have placed the guest's memory and vCPUs together perfectly. But the guest's userspace, trusting the flat map the kernel shows it, pins a hot thread to a vCPU and allocates that thread's buffers wherever it likes - and the moment "wherever" lands on a vnode whose backing memory is a socket away, every access from that thread crosses the interconnect, silently, for as long as the thread runs. Most of the time the guest gets lucky; the rest of the time it has carefully optimised itself onto the slow path, and "the rest of the time" is what operators end up debugging.
Placement is not the only place Xen's split design earns its keep; the scheduler is the other, and on a NUMA host the two are the same problem wearing different hats. On a KVM host the Linux scheduler is responsible for everything at once: guest vCPU threads, the qemu I/O and emulator threads around them, the host kernel's own work, every userspace daemon, every other tenant's workload. They all compete for the same CPU time on the same scheduler. Getting one tenant reliable, fair CPU time under load takes a lot of explicit hand-holding - isolcpus or cgroup cpusets, taskset pinning of every category of thread, scheduler-class changes to fight starvation - and the unified design keeps it a tuning problem no matter how much of that you do.
That same opacity is what makes NUMA hard to get right on a KVM stack. To land a guest's vCPUs and its memory on the same node, you first have to work out which threads inside a qemu (or cloud-hypervisor) process are the vCPUs - as opposed to the I/O threads, the emulator thread, the migration helpers - then pin both the threads and the memory by hand, and keep them lined up as the process spawns more. It is doable, and people do it, but it is fiddly and easy to get subtly wrong, which is exactly how you end up with vCPUs on one node and the memory they touch on another.
Xen's split-scheduler model sidesteps both halves. Xen schedules guest vCPUs onto host pCPUs at the hypervisor layer; the Linux scheduler inside dom0 schedules only dom0's own threads onto dom0's vCPUs. The two layers never compete, because they look at different resources at different levels of abstraction. And because the hypervisor owns vCPU-to-pCPU placement directly, lining a guest's cores and memory up on one node is a decision the toolstack makes once, up front - not something an operator reconstructs out of cgroup primitives and thread spelunking. The same deliberate-up-front instinct as the placement work, one layer down.
Those three decisions are not the whole story, either: there is a fourth dimension that only shows up once you start looking at paravirtual I/O, but that one needs its own setup. For now, the two-stack mismatch is enough to motivate everything that follows.
What's Next in This Series
The next part of this series looks at how Edera makes the placement decisions in items 1 and 2 above, automatically, before any guest starts. The short version: zero configuration in the common case, an explicit escape hatch for workloads that know what they want, and a deliberate preference for consistent performance over peak performance. The longer version is where things get interesting.
Read the Full NUMA Series
NUMA Part 1: Cores, memory, and the distance between them
NUMA Part 2: NUMA-Aware Zone Placement — How Edera Decides
-3.avif)