
Rendering OCI Images the Right Way: Introducing ocirender
OCI image assembly is one of those problems that looks solved until it isn't. The basic mechanics are well-understood, implementations exist everywhere, and for most images most of the time, everything works fine. It's the edge cases that get you — and in our experience, they get you quietly, in ways that are hard to reproduce and even harder to prove you've actually fixed.
For a while, our approach to OCI image assembly inside Edera was to patch the edge cases as we found them. A hard link handled incorrectly here, a whiteout interaction misbehaving there. The fixes were straightforward enough once we had a repro, but the test coverage was thin and the underlying pipeline had never been designed with correctness as a first-class goal. We were playing whack-a-mole, and we knew it. The question wasn't whether there were more gremlins lurking — it was when they'd surface and how bad they'd be when they did.
Eventually the answer to that question became pressing enough that we decided to stop patching and start over.
How OCI Images and Layers Work
An OCI image is not a single filesystem snapshot — it's an ordered stack of layers, each one a tar archive representing the changes made to the filesystem since the previous layer. When you install a package in a Dockerfile, that produces a new layer containing only the files that were added, modified, or removed. The base OS image underneath is a separate layer, or several. Stack them in order and you get the complete filesystem.
Additions and modifications are straightforward: a file present in a layer simply appears in the merged result, with newer layers taking precedence over older ones for the same path. Deletions are trickier. Because a tar archive can only add entries — it has no native concept of "remove this path" — OCI uses a convention called whiteouts. A whiteout is a special marker file whose name encodes the path being deleted. When the merge logic encounters a whiteout for usr/bin/foo, it suppresses any entry at that path from all older layers.
There's also a stronger variant called an opaque whiteout, which suppresses everything under a given directory from older layers, rather than a single path. This is used when a layer replaces an entire directory with new contents — the opaque whiteout clears out whatever the older layers put there, and the new directory contents in the same layer take their place.
Hard links add another wrinkle: a hard link entry in a tar archive references its target by path, and that target might live in an older layer that hasn't been processed yet — or might have been deleted by a whiteout in a newer one. Handling hard links correctly means you can't always emit them immediately; you need to know the full picture of what survives before you can resolve them.
Taken together, these semantics mean that assembling a correct merged filesystem from OCI layers is more involved than it might first appear.
The Problem with "Just Extract It"
When most tools need to produce a usable filesystem from an OCI image, they do roughly the same thing: extract each layer to a temporary directory, apply overlay semantics as they go, and end up with a fully materialized tree on disk. Docker and containerd both work this way, using the kernel's overlayfs to stack layers efficiently at runtime — but that means keeping every layer around as an unpacked directory, consuming disk space proportional to the total uncompressed size of all layers combined.
Edera needed to go further. Rather than stacking live layers, Edera assembles a single squashfs image from the OCI layer set at pull time, then mounts it read-only as the base for the workload's filesystem. A thin writable overlayfs layer on top gives the workload the ability to write to its filesystem without ever modifying the underlying squashfs — keeping the base immutable and content-addressed. This has real security benefits, but it introduces a new challenge: building that squashfs requires producing a complete merged filesystem to hand to mksquashfs.
Our original implementation did roughly this:
- Fetch OCI image metadata: layer list, hashes, compression formats.
- Start downloading all layers concurrently. As each individual layer finishes downloading, immediately extract it to a designated temporary directory, capturing the tar headers for each file as we go.
- Once all layers are downloaded and extracted, build an in-memory Virtual File System (VFS) tree, reading layers in ascending order, applying whiteouts as we go.
- Walk the completed VFS to generate a tar stream, pulling file data from the extracted layer directories using the headers captured at extraction time, and pipe that stream into
mksquashfs -tar. - Clean up the temporaries.
It worked, most of the time. But it had several compounding problems.
Disk space
Peak usage during a pull was proportional to the uncompressed image size: all extracted layer directories were present simultaneously while the squashfs was being written. For GPU workloads — where images routinely include full CUDA runtimes, PyTorch, and entire ML frameworks — this was a genuine operational constraint.
Speed
There was some parallelism: layer downloads and per-layer extraction ran concurrently, so a layer would begin extracting to its temporary directory as soon as it finished downloading. But a hard barrier existed after that point. VFS construction couldn't begin until every layer was downloaded and extracted. Tar stream assembly couldn't begin until the VFS was complete. And mksquashfs couldn't start until the tar stream was ready. The back half of the pipeline was strictly sequential, and on large images — where VFS construction, tar assembly, and squashfs compression each take meaningful time — that barrier was expensive.
Correctness
Overlay filesystem semantics are subtle, and our implementation had edge cases wrong. Hard links were not handled correctly, causing them to be silently dropped from the assembled image. But the deeper problem — and the one that kept finding us in production — was the tar format itself.
The TAR Format Is Full of Footguns
TAR is old. Genuinely old. The format dates to the 1970s, and its age shows. The original USTAR format limits path fields, symlink targets, and hard link targets to 100 bytes. Exceed that limit and the value is silently truncated. This is the kind of bug that's invisible until a customer has a container image with a deeply nested directory structure — then suddenly files disappear, links point nowhere, and nobody immediately understands why.
One of our customers hit exactly this. Their image had a deep directory structure with a large number of small files, many symlinks, and some hard links. Several path and link targets exceeded 100 bytes. Our implementation was reading and re-emitting those truncated values faithfully, producing an image where those entries were silently wrong.
The TAR world's answer to this is PAX extended headers — a mechanism for encoding longer paths, richer metadata, and file sizes that can't fit in the USTAR fields. PAX headers prepend a variable-length key-value block before the main header entry. A correct implementation has to read these, keep them around, and prefer their values over the truncated USTAR fields when both are present. Correct handling also means faithfully re-emitting PAX headers in the output stream, not just reading them — otherwise metadata present in the source layers gets silently dropped on the way to mksquashfs.
We had also previously used a library called tokio-tar for async tar handling. This turned out to be a mistake that went beyond performance. tokio-tar had a bug in its PAX size header handling: when a file was large enough to require a PAX header to express its size, tokio-tar was ignoring that header and reading the USTAR size field instead — which for such files is zero. The result was that when processing a layer containing a large .tar file, tokio-tar would advance by zero bytes instead of the file's actual size, and then begin parsing the inner tar's contents as if they were outer tar entries. We treated this as a security vulnerability — even though it didn't lead to a security compromise in our case, the behavior was undefined and the inputs were potentially attacker-controlled. We disclosed it as CVE-2025-62518, aka TARmaggedon, and switched away from tokio-tar entirely.
Thinking About a Better Way
So the requirements were clear enough: we needed an approach that didn't require extracting layers to disk, didn't accumulate unbounded memory, handled all of the TAR edge cases correctly the first time, and could start producing output before all layers were fully downloaded. The question was whether those constraints could all be satisfied simultaneously, or whether some of them were fundamentally in tension with each other.
The first instinct was appealing in its simplicity: what if we never extracted anything at all? OCI layer blobs are just tar files. The data we need is in there. Why not scan the tars to build an index of which offsets correspond to which files, then mmap the blobs and assemble the squashfs by reading directly from those offsets?
There are two problems with this plan. The first is that OCI layer blobs are almost always compressed — gzip, zstd, bzip2, xz — and you can't mmap a compressed file and seek around in it meaningfully. The second is that even if the layers were uncompressed, random seeking across large tar files isn't particularly cache-friendly. The idea was elegant but not practical.
The second instinct was closer: what if we walked each tar from beginning to end and streamed entries directly into mksquashfs? No temp files. No extraction. Just a pipeline from compressed layer blob to squashfs. The problem here is whiteouts. Once we've written an entry to mksquashfs's stdin, we can't take it back — if a newer layer deletes a file that we already emitted from an older one, there's no way to un-emit it. Without knowing which paths survive into the final filesystem before we start writing, a single forward pass isn't safe. The natural fix is a two-pass approach: scan all layers once to build the VFS and determine which paths survive, then scan them a second time to emit the winners into the output stream. That's workable, but it means decompressing every layer twice. For large images with many gigabytes of compressed layer data, that's a significant cost to pay for what amounts to a bookkeeping problem.
The third instinct was the right one, and it required a small mental shift in how to think about the layer stack. OCI layers aren't meant to be applied oldest-first; they're filesystem snapshot deltas. The newest layer is authoritative. An older layer's entry for a given path only matters if no newer layer has touched that path. So: process layers newest-first. The first time you see a path, that version wins. Every subsequent encounter of the same path in an older layer is simply skipped. Whiteouts become trivial: record them as suppressions and filter against them as you process older layers. Hard links are deferred until all layers are processed, then replayed in order. File data flows directly from the compressed layer blobs through the merge logic and into mksquashfs's stdin — no extraction, no intermediate storage, no memory accumulation.
A Weekend Prototype
One Friday afternoon, deep in a debugging session over yet another OCI image assembly edge case in Edera, the decision was made: spend the weekend writing a prototype that satisfied the hypothesis. The algorithm was clear enough in theory. Time to find out if it held up in practice.
By Saturday evening there was a working implementation in Rust. The core was a reverse-order layer walker with three tracking data structures:
- A path trie (WhiteoutTracker) recording whiteout suppressions, answering "is this path from this layer suppressed?" in O(path depth) time.
- A hash set (EmittedPathTracker) recording every path written to the output, so duplicates in older layers could be skipped in O(1).
- A deferred list (HardLinkTracker) accumulating hard link entries for replay after all layers were processed — including the tricky case of links whose targets were whited out but whose link paths were still live, which needed to be promoted to standalone regular files.
Verification used umoci as a reference implementation — it's a well-tested OCI image unpacker, and diffing our squashfs output against a umoci-unpacked directory gave us a ground truth to check against. The diff was clean on the first real test image. More importantly, the bugs that had plagued the original implementation weren't something we had to hunt down and fix one by one. They simply didn't exist. When overlay semantics are an explicit, self-contained algorithm rather than an emergent property of how a mutable VFS tree gets updated, whole classes of subtle bugs stop being possible in the first place.
ocirender API Design: StreamingPacker, PAX Headers, and Output Formats
The next couple of days expanded the prototype into a proper library. Squashfs was the original target, but the core merge algorithm — merge_layers_into_streaming — produces a standard tar stream to any std::io::Write sink. Wiring it to a file gives a tar output. Wiring it to a UnixStream pair and calling tar::Archive::unpack on the read end gives a directory extraction. All three output formats share the same merge engine with zero duplication.
The more interesting design challenge was the streaming API. Edera downloads layer blobs concurrently as it pulls an image. The original squashfs builder couldn't start until all layers were downloaded. But with the reverse-order algorithm, there was an opportunity: if we start downloading newest-first, we can begin processing layers as they land without waiting for the full download to complete. The StreamingPacker was designed around this idea. It accepts layer blob paths in any arrival order via an async channel, maintains a resequencing buffer to handle out-of-order arrivals, and feeds layers to the merge engine as soon as each one's turn comes. mksquashfs starts immediately and is kept as busy as possible throughout the download.
Getting PAX header handling right was a significant part of the implementation work. The tar crate's Header::link_name() reads only the raw 100-byte USTAR field — returning a silently truncated path for any link target exceeding that limit. We introduced CanonicalTarHeader, which pairs a USTAR header with its PAX extension key-value pairs captured at read time and always prefers the PAX value over the truncated USTAR field. Every header access in the pipeline goes through this type. Of course, this only helps if the source layer was written correctly in the first place — the TAR 100-byte truncation footgun has claimed many implementations over the years, and anyone building tar tooling has probably been bitten by it at least once — but for any well-formed OCI image, ocirender will faithfully preserve the full path and link target data end-to-end.
Getting the algorithm right was one thing; being able to prove it stays right was another. At the time of writing, the new library has over 100 test cases covering cross-layer overlay behavior, both variants of whiteout semantics, PAX header round-tripping, hard link deferral and promotion, and streaming resequencing under every layer arrival order. Because ocirender is a self-contained library with no dependency on the rest of Edera's infrastructure, these tests run in isolation and can be benchmarked and documented independently. When something does regress — and in a codebase that handles a format as old and quirky as TAR, something eventually will — the fix comes with a new test that ensures it never comes back. That kind of robustness is much harder to achieve when the logic is embedded deep in a larger system with no clean seams to test against.
How ocirender Merges OCI Layers: The Overlay Algorithm
At the highest level, converting an OCI image with ocirender looks like this:
layer blobs (gzip/zstd/etc)
│
│ decompress on the fly
▼
tar entry stream ─── overlay merge ───► merged tar stream
(per layer) (in memory) │
├─► mksquashfs stdin → .squashfs
├─► file → .tar
└─► tar::unpack → directoryThe overlay merge is the heart of it. Processing layers in descending index order, for each entry the engine:
- Checks if it's a whiteout entry. If so, records the suppression and moves on. Whiteout entries are never emitted.
- Checks if the path is suppressed by a previously-seen whiteout from a newer layer. If so, the entry is skipped — but for regular files, the content is held briefly in case a hard link in the same layer needs it for promotion.
- Checks if the path has already been emitted. If so, a newer layer already won; skip.
- For hard links, defers the entry for replay after all layers are complete.
- For everything else, streams the entry — header and file data — directly into the output sink.
After all layers are processed, deferred hard links are replayed. Any link whose target was suppressed by a whiteout is promoted to a standalone regular file; if multiple links share the same suppressed target, they form a group with one primary file and the rest as hard links to it, preserving inode identity for tools like rsync and du.
The only in-memory state is the three tracking structures and the small deferred hard link list. File data is never staged anywhere between the compressed layer blob and the output sink.
Integration and Image Pull Performance Testing
The new implementation was integrated into Edera the following week. The OCI assembly bugs that had been accumulating — some subtle, some only surfacing under specific image layouts — were gone. One class of image that had been particularly problematic was images with deep directory structures, large numbers of small files, extensive use of symlinks, and hard links whose targets exceeded the 100-byte USTAR field limit. The combination of PAX mishandling and whiteout interaction bugs had been making those images produce subtly broken filesystems. Both classes of bug were simply gone.
To measure the performance improvement fairly, test images were mirrored to a LAN-local registry on a 10GbE network and pulled with cleared caches, so all layers were fetched fresh each time over a real network path rather than from localhost. Times below include the full layer download and image assembly end-to-end (i.e. docker pull and protect image pull).
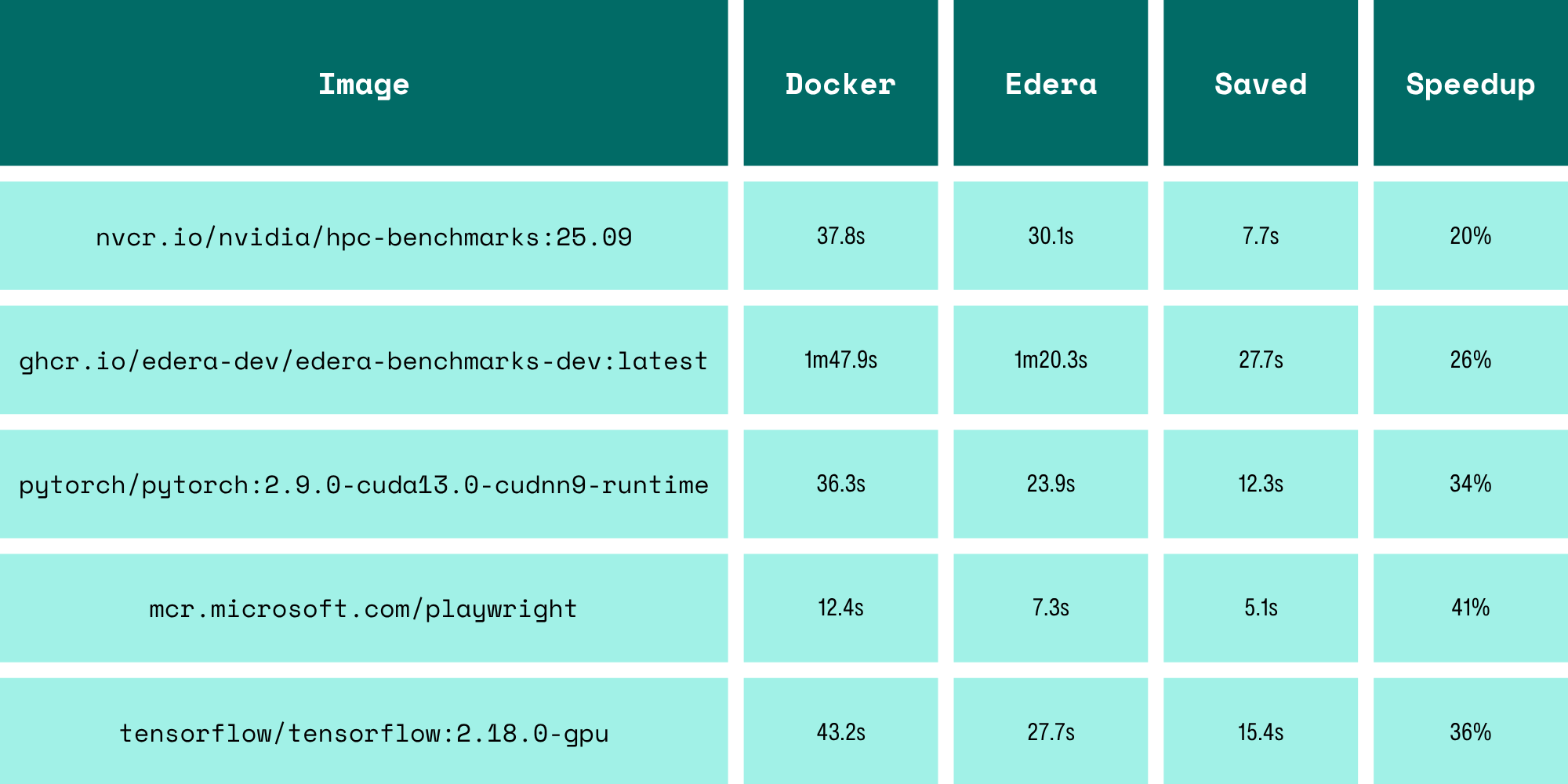
Across these five images — all real-world GPU and ML workloads with large, heavily layered images — Edera pulled an average of 31% faster than Docker.
What makes these numbers particularly interesting is that Edera is doing significantly more CPU work than Docker during a pull. Docker's overlayfs approach simply unpacks each layer as a directory — relatively cheap I/O work. Edera is assembling a merged tar stream and then running mksquashfs with zstd compression on top of that. That's a non-trivial amount of additional computation. The fact that we come out ahead despite the heavier CPU load is a direct consequence of the streaming pipeline: mksquashfs is compressing data while remaining layers are still being downloaded, whereas Docker must finish downloading and unpacking everything before the image is ready to use. We're doing more work per CPU cycle and still finishing sooner.
The disk space improvement is similarly pronounced. Where Docker's overlayfs approach stores every layer unpacked indefinitely, and our previous approach needed scratch space proportional to the full uncompressed image size during assembly, the new pipeline requires only the compressed layer blobs during download and the final squashfs at the end. For a large GPU image, the difference can be tens of gigabytes of temporary storage that simply no longer exists.
Try It
ocirender is available on crates.io. Full API documentation is on docs.rs. The public API is straightforward: describe your output target with an ImageSpec, call convert() for batch use or set up a StreamingPacker for concurrent download-and-assemble workflows, and call verify::verify() to diff the result against a reference.
We're also thinking about additional output formats — erofs is on the list for its read performance characteristics in certain workloads. The architecture makes adding new output sinks straightforward: the merge engine doesn't know or care what it's writing to.
If you're building anything in this space, we'd love to hear from you.
FAQ
What is ocirender?
ocirender is a Rust library for assembling OCI container images into squashfs, tar, or directory output formats. It processes OCI image layers in reverse order using an in-memory overlay merge engine, requiring no intermediate extraction to disk and streaming file data directly from compressed layer blobs to the output sink.
How does ocirender handle OCI layer whiteouts?
ocirender processes layers from newest to oldest. When it encounters a whiteout entry, it records the suppression in a path trie (WhiteoutTracker) and filters all matching entries in older layers.
What TAR edge cases does ocirender handle correctly?
ocirender introduces CanonicalTarHeader, which pairs each USTAR header with its PAX extended header key-value pairs and always prefers the PAX value. This preserves all extended metadata, including large sizes, long paths, extended attributes, and so on. The data is passed unmodified through the pipeline into the output, preventing any of the typical PAX-related edge cases.
How does ocirender improve OCI image pull performance?
By processing layers in reverse order and streaming file data directly into mksquashfs without extracting to disk, ocirender allows layers to be processed even while other remaining layers are still downloading. Across five GPU and ML workloads tested on a 10GbE LAN-local registry, ocirender pulled an average of 31% faster than Docker despite performing additional CPU work to create a compressed squashfs image.
What is CVE-2025-62518 (TARmageddon) and how does it relate to ocirender?
CVE-2025-62518 is a boundary-parsing bug in the tokio-tar Rust library where the parser read the USTAR size field (zero) instead of the PAX size field for large files, causing it to treat inner tar contents as outer tar entries. Edera disclosed this vulnerability and switched away from tokio-tar entirely when building ocirender, which uses a custom canonical header type to ensure correct PAX handling.
What output formats does ocirender support?
ocirender's merge engine produces a standard tar stream to any std::io::Write sink. This can be wired to mksquashfs stdin to produce a squashfs image, written to a file to produce a tar archive, or unpacked to a directory. All three output paths share the same merge engine.
-3.avif)