
What Every Cloud Native Engineer Needs to Know About Kernel Memory
A companion post to my Cloud Native Rejekts talk: "Your AI Agent Has a Kernel Problem."
Your AI agent just ran for 35 minutes. You instructed it to read your codebase, analyze it for vulnerabilities, draft a report, and start fixing them, and then it got OOMKilled 75% of the way in. You lost all progress, every file it read, every intermediate conclusion, every token of reasoning. Poof.
You check your monitoring dashboard. Container memory usage: 78%. Was it a memory leak? Was the agent just doing its job and accumulating context? Should you increase the limit or file a bug?
You don't know and your monitoring stack can't tell you. The information you need to answer that question doesn't exist in the metrics you're collecting.
What every programmer needs to know about memory
In 2007, Ulrich Drepper published "What Every Programmer Should Know About Memory." It's the canonical computer science reference of the memory hierarchy from CPU registers through L1/L2/L3 caches to DRAM to disk. Registers at the top: tiny, fast, expensive. DRAM in the middle: big, slower, cheap (at least it was before AI). Disk at the bottom: massive, glacial, nearly free.
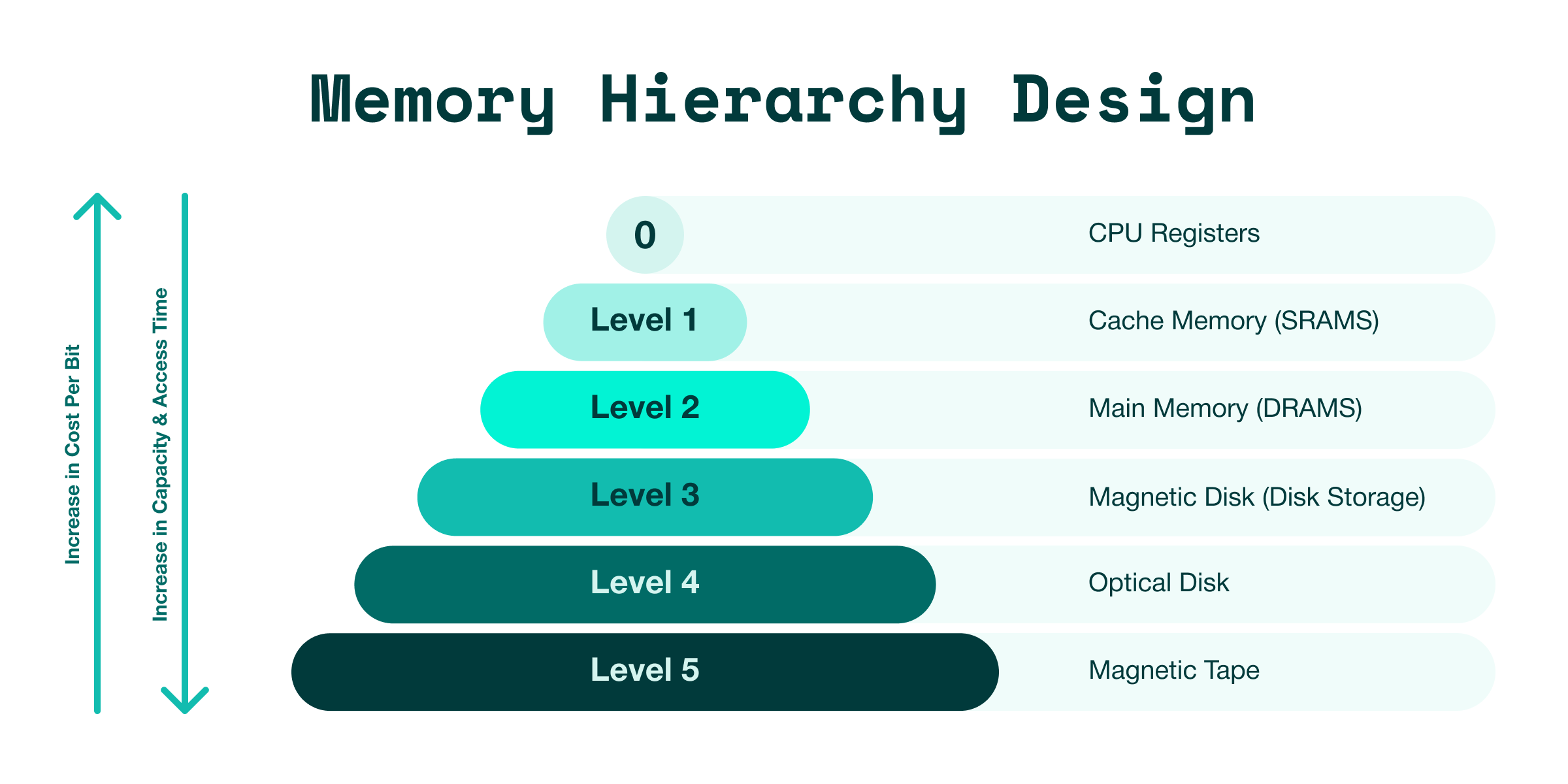
This isn't nerd trivia. The kernel's entire job is to make this hierarchy disappear and create the illusion of infinite, fast memory by shuttling data between the layers automatically. Every Computer Science graduate learns this pyramid and then they deploy to Kubernetes and forget all of it. Not because they're lazy, because the abstraction told them to. Cloud native engineers think of memory in binary, free and used.
The shadow on the wall
Plato's cave allegory applies here: cgroups memory metrics are the shadows on the wall.
When you run kubectl top pod or look at container memory in Grafana, you see memory.current - the number of bytes charged to your container's cgroup. Your monitoring stack turns this into a percentage: "78% of limit." Maybe it draws a nice time-series graph or fires a PagerDuty alert when it reaches 90%.
Here's what that number doesn't tell you:
- How much of that 78% is your application's actual heap versus the kernel's page cache (disk files cached in RAM for performance)
- How much is reclaimable? Memory the kernel can free instantly without affecting your application
- How much headroom you actually have before the kernel starts struggling to find memory for your allocations
- Whether the kernel is quietly thrashing behind the scenes, scanning page lists and evicting caches just to keep your application alive
The three-dimensional metric you need is MemAvailable. This is the kernel's authoritative answer to: "how much memory can this workload allocate right now without triggering the OOM killer?"
MemAvailable has no cgroup equivalent. It doesn't exist in memory.stat, memory.current, or any metric your container monitoring stack collects. The kernel computes it on every read of /proc/meminfo by accounting for free pages, reclaimable cache, and reclaimable slab. It's the single most useful number for understanding whether your workload is healthy or about to run out of memory and crash.
And it's invisible from inside a container on a shared kernel. When you read /proc/meminfo from a container, you get the node's MemAvailable - 64GB spread across 50 pods. Complete noise for per-workload performance monitoring.
I want to be precise about this: cgroups aren't lying to you. The cgroups maintainers built a correct and useful abstraction for resource accounting and limit enforcement. memory.current accurately represents bytes charged to your cgroup. memory.max correctly enforces the configured limit. This is working as intended. The lie is in how we interpret these numbers.
"Container memory usage: 78%" implies you understand the memory state of your workload. You understand the accounting state. And accounting, by definition, loses information. The question is whether the lost information matters? For years, it mostly didn't. Stateless microservices have simple memory patterns: allocate memory per request, free after response, rinse and repeat. If you're at 78% and climbing, you probably need more memory.
But "probably" is doing a lot of work in that sentence. The kernel doesn't see memory as "used" and "free." It sees a continuum: anonymous pages (your heap), page cache (disk files cached in RAM), reclaimable slab, dirty buffers. The kernel's entire strategy is: use every byte of RAM for something useful, and reclaim when something more important needs it. Free memory is wasted memory. A healthy system often shows very low free memory because the kernel fills RAM with page cache because cached disk reads are 1000x faster than uncached ones.
When your monitoring dashboard shows "78% used" and you reach for the pager, you're looking at a shadow. The kernel might have 1.2GB of reclaimable page cache in that 78%. Your workload might have 40% headroom or it might have 2%. The shadow can't tell you which.
What the kernel actually knows
I gave a talk at Cloud Native Rejekts where I ran Claude Code inside an Edera zone with a dedicated Linux kernel. Our userspace zone binary reads /proc and exports the metrics to Prometheus. Here's what the kernel told us - not shadows, but the actual state of memory behind the wall:
MemAvailable started at 850 MB and declined to ~480 MB over 5 minutes. A 44% drop. Traditional monitoring would show "memory usage climbing toward limit" and potentially alert. But the decline was expected - each step corresponded to a tool call being added to the agent's context. Not a smooth decline (which would indicate a leak), but a discrete decline corroborated with agent actions. The kernel knew the difference, cgroups couldn't.
Page faults (major) were near zero the entire time. This is the signal that matters. A major page fault means the kernel had to fetch data from disk which is 1000x slower than RAM in the memory hierarchy. Zero major faults means everything fit in allocated memory. If this number were climbing, you'd know your workload needs more RAM before any application-level metric could tell you.
Context switches were ~400/s during file reading and ~330/s during report writing. Each context switch is the kernel handing the CPU from one process to another. Claude's tool calls cause this: fork a child process, run grep, collect output, fork another. On a shared kernel, this number includes every pod on the node. Here, it's just the agent's dedicated kernel.
None of these metrics are exotic. They've been in /proc since the 90s. The same counters every Linux performance engineer has used for decades. The only thing that changed is scope: on a shared kernel, they're node-wide noise. On a dedicated kernel, they're a per-workload signal. The shadows become reality.

The platform engineering tradeoff
I spent years as a platform engineer and the industry made a correct tradeoff with the information available at the time: developers shouldn't have to think about infrastructure. Abstract away node management, networking, storage, deployment pipelines. Give them kubectl apply and a dashboard. This unlocked unparalleled velocity.
The platform engineering contract was: we'll give you cgroups metrics because that's the best per-workload data that exists on a shared kernel. Container memory percentage, CPU throttling, restart counts. Shadows, yes, but sufficient shadows for workloads where a restart costs one failed HTTP request.
But containerized workloads have changed and the tradeoff should change with them. AI agents run for minutes to hours. They accumulate state that can't be reconstructed, and their memory patterns look pathological to traditional monitoring but are perfectly healthy from the kernel's perspective. An OOMKill doesn't cost a single HTTP request that takes 100ms to serve – it costs 35 minutes of compute and the entire reasoning chain.
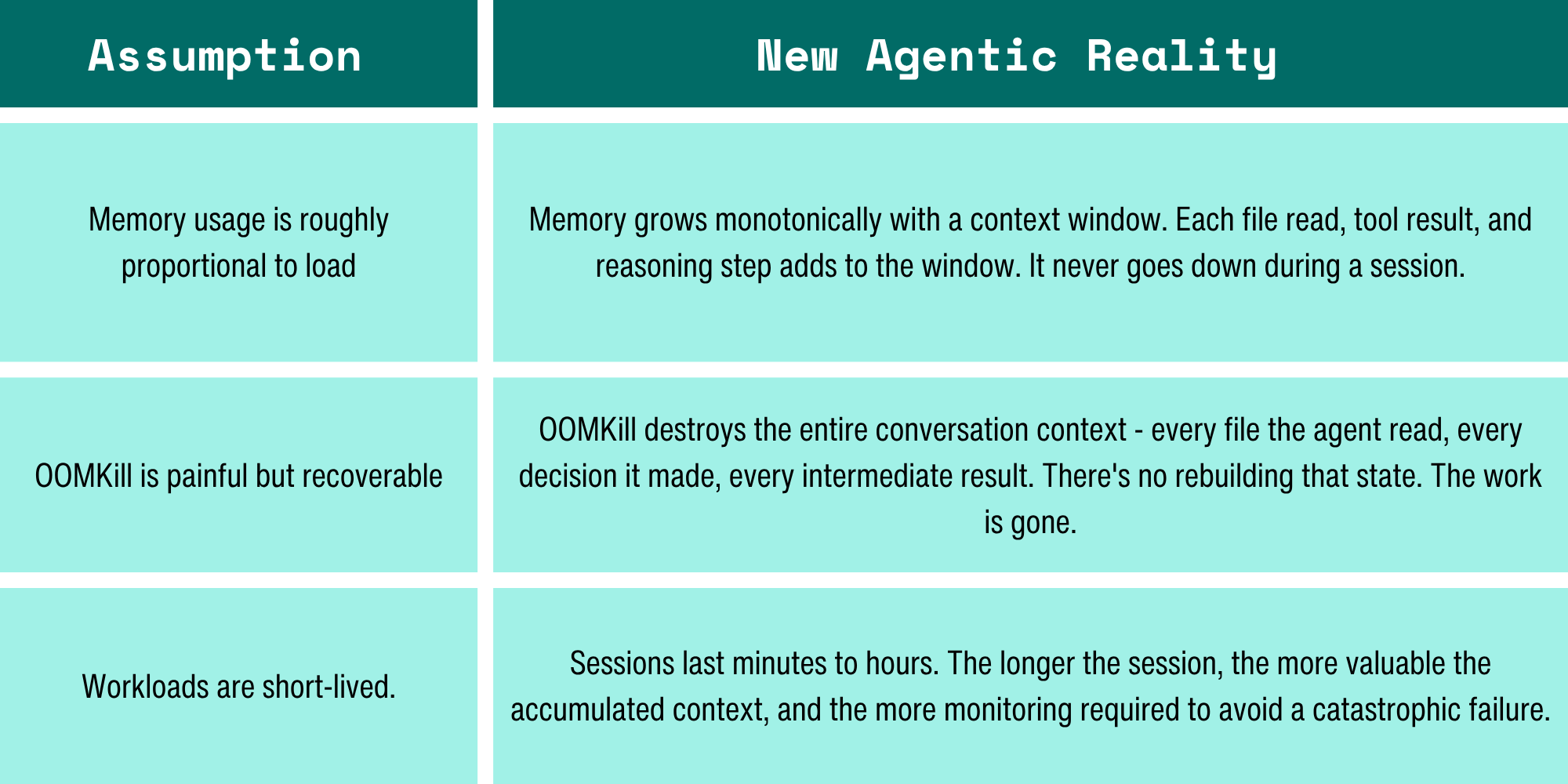
Why AI agents break the model
Every assumption in container monitoring was designed for stateless microservices:
The industry already decided that AI agents need dedicated kernels for security. You can't let an agent that executes arbitrary code share a kernel with your production database. Sandboxing via microVMs or equivalent is the standard pattern.
What isn't being talked about is that dedicated kernels are the only architecture that gives you per-workload kernel metrics - the only way to turn the shadows into the real thing. When security and observability converge on the same solution, you get both for the price of one.
"Just use eBPF"
I can hear the Hacker News comments already.
eBPF is amazing. I love eBPF. I wrote a book on eBPF. You can trace syscalls per process, analyze network flows, profile function latency. But eBPF reads kernel state, it doesn't isolate it. MemAvailable is a global counter, PSI is a global counter, memory reclaim is a global event. eBPF can observe these, but it can't attribute them to a specific pod because the kernel doesn't track them per-cgroup. It can't, because they're properties of the kernel's memory manager, not the cgroup's resource accounting.
With a dedicated kernel, every counter is per-workload by definition. And you can also run eBPF inside the zone for deeper tracing, with full root access, without needing cluster-admin permissions. eBPF gives you surgical data on a shared kernel. They're complementary, not competing.
Getting out of the cave
The cloud-native community has spent a decade abstracting away the kernel and that was the right call for the constraints that existed. But the constraints have changed: per-workload kernels exist, per-workload kernel metrics are possible, and the workloads demand it. AI agents accumulate irreplaceable state and exhibit memory patterns that look pathological to cgroups but healthy to the kernel.
The kernel isn't legacy infrastructure to hide from developers. It's the source of truth about what their code is actually doing. It always has been. We just didn't need to remove the abstraction until now.
It's time to leave the cave.
Want to know more? Watch the full talk and access the slides.
-3.avif)