
Edera Makes Running Privileged Containers Safe, and Secure by Default
In today's cloud-native environments, organizations face a persistent dilemma: how to run privileged containers securely without compromising performance or adding complexity. The upcoming Edera Protect 1.1 release addresses this challenge head-on by introducing privileged mode support – a feature that allows workloads requiring elevated privileges to operate within Edera Protect's strong isolation architecture.
Edera Protect is our secure-by-design container-native hypervisor. While traditional container runtimes rely on Linux namespaces for isolation – which can be escaped – Edera Protect treats containers like virtual machine guests, providing strong security guarantees without performance tradeoffs.
It safely enables privileged containers through effective isolation, allowing security-sensitive workloads to run with elevated access while maintaining strong security boundaries. This unlocks new use cases while reducing risk.
What Are Privileged Containers and Why Do They Matter?
Privileged containers have long been considered a security risk because they bypass many of the isolation mechanisms that normally protect host systems. When a container runs in privileged mode (i.e., –privileged), it shares the same user namespace as the host and gains an extensive set of capability bits that allow it to perform operations typically restricted to the host system.
Many organizations face these common scenarios requiring privileged mode:
- CI/CD pipelines that need to build and test container images
- Security tools that require deep system access
- Network CNIs that manage container and host interfaces
- Storage management utilities that need to interact with host devices
However, running these workloads in privileged mode traditionally means accepting significant security risks – until now.
Traditional approaches to privileged containers come with significant drawbacks:
- Shared kernel vulnerabilities: Container escapes can lead to full host compromise
- Lateral movement opportunities: Attackers can pivot across multiple containers
- Limited blast radius containment: Security incidents can quickly cascade
Security Alert: Privileged containers in traditional environments have full access to the host system and are considered a primary vector for container escapes.
How Edera Protect Makes Privileged Mode Safe
Coming in the next major release of Edera Protect, we have added support for privileged mode, allowing for containers requiring privileged access to work in isolation on the Edera Protect platform, which unlocks new potential for reducing the risks of running these workloads.
First, let's talk about the caveats and best practices…
Privileged mode on Edera Protect is designed for workloads that require elevated privilege but can otherwise be isolated, such as CI/CD build jobs and other ephemeral workloads which require privilege. It is not designed to be a drop-in replacement for workloads that modify the host machine – those workloads should continue to be run as standard containers without isolation.
In addition, we generally recommend running privileged workloads in their own isolated zones – our next-gen kubernetes sandbox – whenever possible, to ensure that other workloads are protected from the privileged workload’s elevated access.
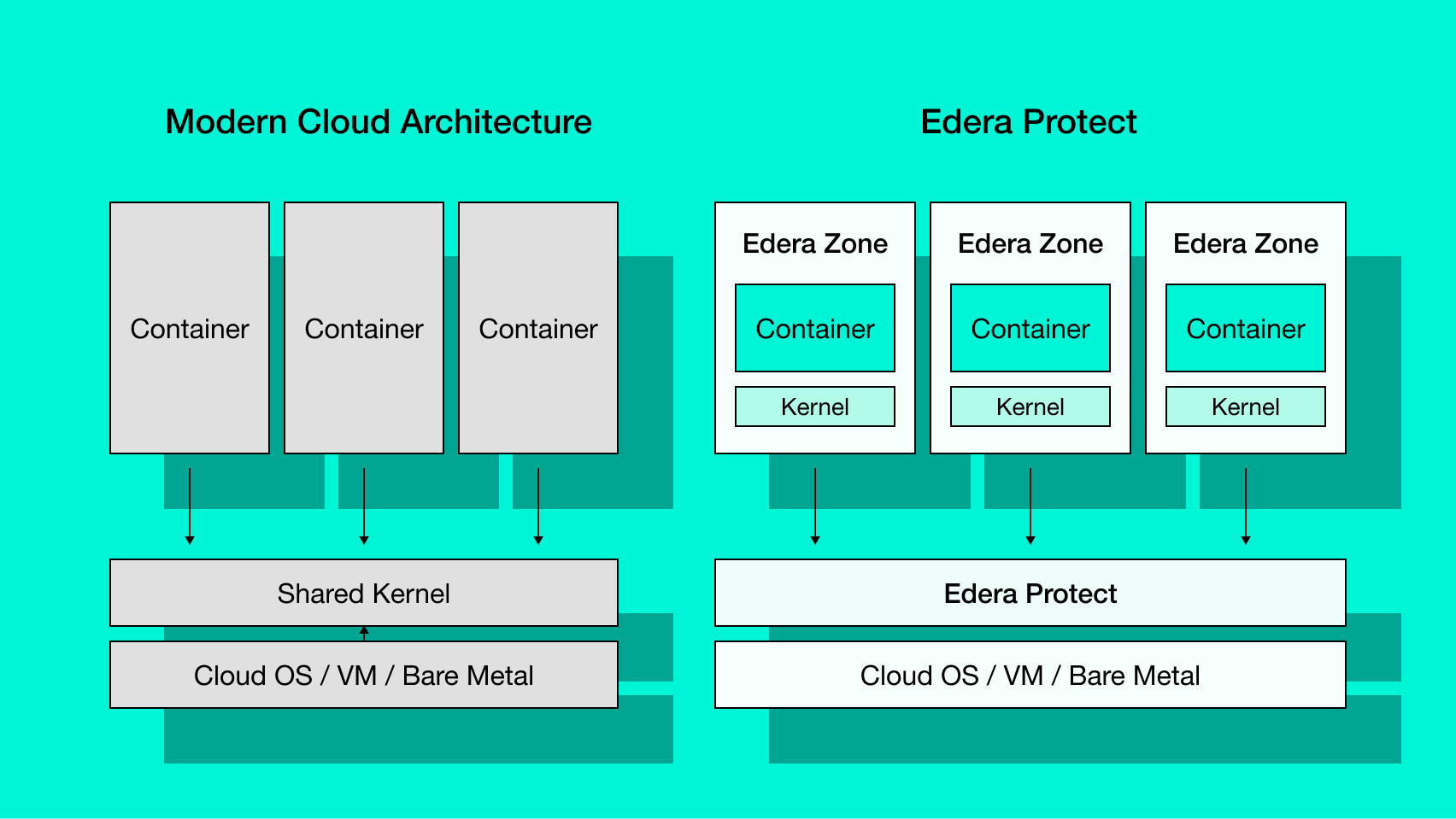
What is privileged mode anyway?
Normally, when OCI containers – the most common and widely adopted format for container images – are run, they are run in unprivileged mode: they have their own user namespaces which cannot inherit privilege from the primary user namespace used by the host system. Privileged mode flips the script: when you run a container as a privileged one, it shares the same user namespace as the host, meaning that the containerized environment has full access to the host’s resources.
Besides the lack of a user namespace, privileged mode primarily works by granting a default set of capability bits. If we use a tool like Docker or Podman, we can directly observe how privileged mode differs from unprivileged mode. First, let's look at an unprivileged container:
What you can see from the output is that in the unprivileged container, the capability sets (CapPrm, CapEff, CapBnd) are limited: 00000000a80425fb is a partial set of Linux capabilities.
Now to compare, we can look at a privileged one:
In the privileged container, those sets are: 000001ffffffffff — This represents all capabilities (full 64-bit mask).
Some capability bits work within user namespaces and apply only to resources controlled by that specific namespace. Others—like CAP_SYSLOG, which lets you read and clear the kernel log buffer—are only effective in the initial (host) user namespace. To illustrate, we can compare between a privileged and unprivileged container with the CAP_SYSLOG capability added. First, let’s try to read the kernel log buffer in a totally unprivileged container:
As expected, reading the log buffer is not allowed because the kernel does not allow access to it by default. What happens if we give ourselves CAP_SYSLOG?
It works, but only because Docker does not use user namespaces by default which allows CAP_SYSLOG to be meaningful. We can verify this by using Edera’s am-i-isolated tool:
If we restart Docker with user namespace support enabled, we get:
Now, if we try to use CAP_SYSLOG, it should be ineffective:
In contrast to Docker and Kubernetes, the Edera Protect platform uses user namespaces by default as an additional form of hardening, so privileged mode on Edera Protect automatically drops the use of user namespaces for compatibility.
Capability enforcement in the kernel
Why is it that CAP_SYSLOG doesn’t work inside a user namespace? To get to the bottom of it, we need to look at the kernel.
The kernel privilege model is built around POSIX capabilities: small bits which, if set on a process, allow it to perform privileged operations. In this privilege model, the root user has a default effective capability set comprising all known capability bits available in the kernel, which is 41 bits as of Linux 5.9, the last time a new capability was added to the kernel.
By shifting superprivilege away from the root user (which retains superprivilege by default) into capability bits, a few things are unlocked:
- Applications started with superprivilege can voluntarily lower their capability bits
- Applications started without superprivilege can have select capability bits enabled, either through a launcher or through filesystem attributes
- Users who are not root can be granted select capability bits allowing for limited privileged operations without the need for sudo
But how does this work in practice? In the example above, we granted the CAP_SYSLOG capability, but it is ineffective. To find out why, let's take a look at our CAP_SYSLOG example from the perspective of the kernel. When a user requests the kernel log buffer, they perform a klogctl(2) syscall.
If we browse the source code for the klogctl syscall, we see the following fragment:
The main function of interest here is capable(), which is used by the kernel to determine if the current process has the appropriate capability in the initial user namespace, &init_user_ns:
ns_capable() is just a wrapper around ns_capable_common(), which is a wrapper around the LSM capable hook:
We can find the appropriate hook in the POSIX capabilities LSM (with the author’s annotations in the comments):
Given this, we can deduce the following rules for capability bits:
- Users which create unprivileged user namespaces are treated like the root user in the initial user namespace, but only over resources governed by the namespace.
- Capabilities only propagate downward, not back towards the initial user namespace. This is why
CAP_SYSLOGis meaningless in a user namespace, for example.
Coming to Edera Protect 1.1
Privileged mode support will be available in the upcoming Edera Protect 1.1 release. This feature enables organizations to:
- Consolidate infrastructure by running privileged workloads on the same clusters as unprivileged ones
- Improve security posture by containing privileged operations within isolated zones
- Simplify operations with a consistent platform for all workloads
- Reduce costs by eliminating the need for separate dedicated infrastructure
To learn more about how Edera Protect's privileged mode can help secure your sensitive workloads, or to test out a beta version get in touch.
By combining the flexibility of privileged containers with the strong isolation guarantees of Edera Protect, organizations can run sensitive workloads more securely than ever before.
-3.avif)